機械学習の概要
序章
機械学習は、人工知能(AI)のサブフィールドです。 機械学習の目標は、一般に、データの構造を理解し、そのデータを人々が理解して利用できるモデルに適合させることです。
機械学習はコンピュータサイエンスの分野ですが、従来の計算アプローチとは異なります。 従来のコンピューティングでは、アルゴリズムは、コンピューターが計算または問題解決に使用する、明示的にプログラムされた命令のセットです。 代わりに、機械学習アルゴリズムにより、コンピューターはデータ入力をトレーニングし、統計分析を使用して特定の範囲内の値を出力できます。 このため、機械学習は、データ入力に基づく意思決定プロセスを自動化するために、コンピューターがサンプルデータからモデルを構築するのを容易にします。
今日のテクノロジーユーザーなら誰でも、機械学習の恩恵を受けています。 顔認識技術により、ソーシャルメディアプラットフォームは、ユーザーが友人の写真にタグを付けて共有するのに役立ちます。 光学式文字認識(OCR)テクノロジーは、テキストの画像を活字に変換します。 機械学習を利用したレコメンデーションエンジンは、ユーザーの好みに基づいて、次に視聴する映画やテレビ番組を提案します。 機械学習に依存してナビゲートする自動運転車は、間もなく消費者に利用可能になる可能性があります。
機械学習は継続的に発展している分野です。 このため、機械学習の方法論を使用したり、機械学習プロセスの影響を分析したりする際には、いくつかの考慮事項に留意する必要があります。
このチュートリアルでは、監視付き学習と監視なし学習の一般的な機械学習方法と、k-nearest neighborアルゴリズム、決定木学習、深層学習など、機械学習における一般的なアルゴリズムアプローチについて説明します。 機械学習で最も使用されているプログラミング言語を調べ、それぞれの良い点と悪い点をいくつか紹介します。 さらに、機械学習アルゴリズムによって永続化されるバイアスについて説明し、アルゴリズムを構築するときにこれらのバイアスを防ぐために何を念頭に置くことができるかを検討します。
機械学習の方法
機械学習では、タスクは一般的に広いカテゴリに分類されます。 これらのカテゴリは、学習がどのように受け取られるか、または学習に関するフィードバックが開発されたシステムにどのように提供されるかに基づいています。
最も広く採用されている機械学習方法の2つは、人間がラベル付けした入力データと出力データの例に基づいてアルゴリズムをトレーニングする教師あり学習と、ラベルなしのアルゴリズムを提供する教師なし学習です。入力データ内の構造を見つけることができるようにするためのデータ。 これらの方法をさらに詳しく見ていきましょう。
教師あり学習
教師あり学習では、コンピューターには、目的の出力でラベル付けされた入力例が提供されます。 この方法の目的は、アルゴリズムが実際の出力を「教えられた」出力と比較してエラーを見つけ、それに応じてモデルを変更することによって「学習」できるようにすることです。 したがって、教師あり学習では、パターンを使用して、追加のラベルなしデータのラベル値を予測します。
たとえば、教師あり学習では、fishとラベル付けされたサメの画像とwaterとラベル付けされた海の画像を含むデータがアルゴリズムに供給される場合があります。 このデータでトレーニングすることにより、教師あり学習アルゴリズムは、ラベルのないサメの画像をfishとして、ラベルのない海の画像をwaterとして後で識別できるようになります。
教師あり学習の一般的な使用例は、履歴データを使用して統計的に可能性の高い将来のイベントを予測することです。 過去の株式市場情報を使用して、今後の変動を予測したり、スパムメールを除外したりする場合があります。 教師あり学習では、犬のタグ付き写真を入力データとして使用して、犬のタグなし写真を分類できます。
教師なし学習
教師なし学習では、データにラベルが付けられていないため、学習アルゴリズムは入力データ間の共通点を見つけるために残されています。 ラベルなしデータはラベル付きデータよりも豊富であるため、教師なし学習を容易にする機械学習手法は特に価値があります。
教師なし学習の目標は、データセット内の隠れたパターンを発見するのと同じくらい簡単かもしれませんが、生データを分類するために必要な表現を計算機が自動的に発見できるようにする特徴学習の目標も持つ可能性があります。
教師なし学習は、トランザクションデータに一般的に使用されます。 顧客とその購入の大規模なデータセットがあるかもしれませんが、人間として、顧客のプロファイルとその購入のタイプからどのような類似の属性を引き出すことができるかを理解できない可能性があります。 このデータを教師なし学習アルゴリズムに入力すると、無香料の石鹸を購入する特定の年齢層の女性が妊娠している可能性が高いと判断される可能性があります。したがって、妊娠とベビー用品に関連するマーケティングキャンペーンをこのオーディエンスに順番にターゲティングできます。購入数を増やすため。
「正しい」答えを言われることなく、教師なし学習方法は、潜在的に意味のある方法でデータを整理するために、より広範で一見無関係に見える複雑なデータを調べることができます。 教師なし学習は、クレジットカードの不正購入や、次に購入する製品を推奨するレコメンダーシステムなど、異常検出によく使用されます。 教師なし学習では、犬のタグなし写真をアルゴリズムの入力データとして使用して、類似点を見つけ、犬の写真を一緒に分類できます。
アプローチ
分野として、機械学習は計算統計と密接に関連しているため、統計の背景知識を持つことは、機械学習アルゴリズムを理解して活用するのに役立ちます。
統計を研究したことがない人にとっては、最初に相関と回帰を定義することが役立つ場合があります。これらは、量的変数間の関係を調査するために一般的に使用される手法だからです。 相関は、従属または独立として指定されていない2つの変数間の関連の尺度です。 基本レベルの回帰は、1つの従属変数と1つの独立変数の間の関係を調べるために使用されます。 独立変数がわかっている場合、回帰統計を使用して従属変数を予測できるため、回帰により予測機能が有効になります。
機械学習へのアプローチは継続的に開発されています。 ここでは、執筆時点で機械学習で使用されている一般的なアプローチをいくつか紹介します。
k最近傍
k最近傍アルゴリズムは、分類と回帰に使用できるパターン認識モデルです。 多くの場合、k-NNと略され、k最近傍の k は正の整数であり、通常は小さいです。 分類または回帰のいずれにおいても、入力は空間内のk個の最も近いトレーニング例で構成されます。
k-NN分類に焦点を当てます。 このメソッドでは、出力はクラスメンバーシップです。 これにより、k最近傍の中で最も一般的なクラスに新しいオブジェクトが割り当てられます。 k = 1の場合、オブジェクトは単一の最近傍のクラスに割り当てられます。
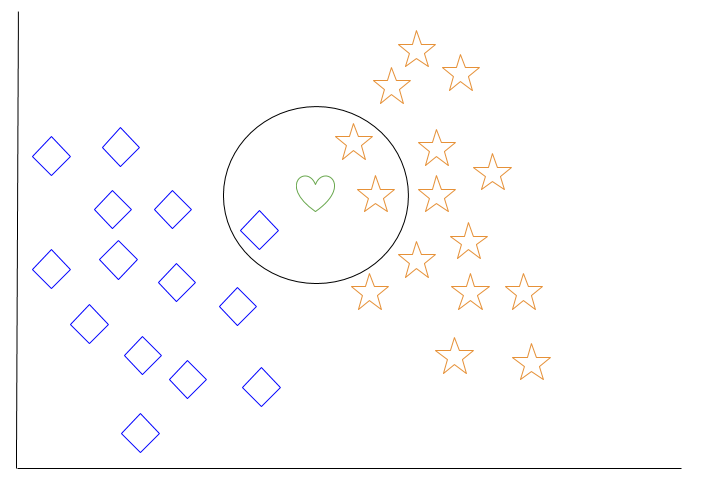
k最近傍法の例を見てみましょう。 下の図には、青いひし形のオブジェクトとオレンジ色の星のオブジェクトがあります。 これらは、ダイヤモンドクラスとスタークラスの2つの別々のクラスに属しています。

新しいオブジェクト(この場合は緑色のハート)がスペースに追加されると、機械学習アルゴリズムでハートを特定のクラスに分類する必要があります。

k = 3を選択すると、アルゴリズムは、緑色のハートの3つの最近傍を見つけて、それをダイヤモンドクラスまたはスタークラスのいずれかに分類します。
私たちの図では、緑色のハートの3つの最近傍は、1つのダイヤモンドと2つの星です。 したがって、アルゴリズムは心臓をスタークラスで分類します。
機械学習アルゴリズムの最も基本的なものの中で、k最近傍法は、システムに対してクエリが実行されるまでトレーニングデータを超える一般化が発生しないため、一種の「レイジーラーニング」と見なされます。
決定木学習
一般的な使用では、意思決定ツリーを使用して、意思決定を視覚的に表現し、意思決定を表示または通知します。 機械学習とデータマイニングを使用する場合、決定木が予測モデルとして使用されます。 これらのモデルは、データに関する観察結果をデータの目標値に関する結論にマッピングします。
デシジョンツリー学習の目標は、入力変数に基づいてターゲットの値を予測するモデルを作成することです。
予測モデルでは、観測によって決定されたデータの属性はブランチで表され、データのターゲット値に関する結論はリーフで表されます。
ツリーを「学習」する場合、ソースデータは属性値テストに基づいてサブセットに分割されます。このテストは、派生したサブセットのそれぞれで再帰的に繰り返されます。 ノードのサブセットがそのターゲット値と同等の値になると、再帰プロセスが完了します。
誰かが釣りに行くべきかどうかを決定することができるさまざまな条件の例を見てみましょう。 これには、気象条件と気圧条件が含まれます。
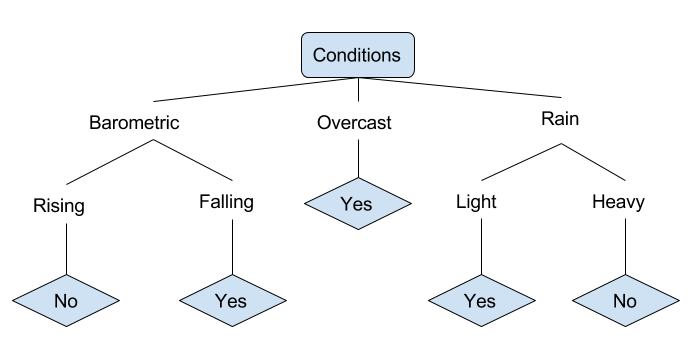
上記の簡略化された決定木では、例はツリーを介して適切なリーフノードにソートすることによって分類されます。 次に、特定の葉に関連付けられた分類を返します。この場合は、YesまたはNoのいずれかです。 釣りに適しているかどうかに基づいて、1日の状態を分類します。
真の分類ツリーデータセットには、上記で概説したものよりもはるかに多くの機能がありますが、関係を簡単に判断できる必要があります。 デシジョンツリー学習を使用する場合、選択する機能、分割に使用する条件、デシジョンツリーが明確な終わりに達したときの理解など、いくつかの決定を行う必要があります。
ディープラーニング
ディープラーニングは、人間の脳が光と音の刺激を視覚と聴覚に処理する方法を模倣しようとします。 ディープラーニングアーキテクチャは、生物学的ニューラルネットワークに触発され、ハードウェアとGPUで構成される人工ニューラルネットワークの複数のレイヤーで構成されています。
深層学習では、データの特徴(または表現)を抽出または変換するために、非線形処理ユニットレイヤーのカスケードを使用します。 1つのレイヤーの出力は、後続のレイヤーの入力として機能します。 深層学習では、アルゴリズムを教師ありでデータの分類に使用することも、教師なしでパターン分析を実行することもできます。
現在使用および開発されている機械学習アルゴリズムの中で、深層学習はほとんどのデータを吸収し、いくつかの認知タスクで人間を打ち負かすことができました。 これらの属性のために、ディープラーニングは人工知能の分野で大きな可能性を秘めたアプローチになりました
コンピュータビジョンと音声認識はどちらも、ディープラーニングアプローチからの重要な進歩を実現しています。 IBM Watsonは、ディープラーニングを活用するシステムのよく知られた例です。
プログラミング言語
機械学習に特化する言語を選択するときは、現在の求人広告に記載されているスキルと、機械学習プロセスに使用できるさまざまな言語で利用可能なライブラリを検討することをお勧めします。
2016年12月にindeed.comの求人広告から取得したデータから、Pythonは機械学習の専門分野で最も人気のあるプログラミング言語であると推測できます。 Pythonの後にJava、R、C++の順に続きます。
Python の人気は、 TensorFlow 、 PyTorch 、