手話を英語に翻訳するニューラルネットワークを構築する方法
著者は、 Write for DOnations プログラムの一環として、寄付を受け取るために CodeOrgを選択しました。
序章
コンピュータビジョンは、画像やビデオから高次の理解を引き出すことを目的としたコンピュータサイエンスのサブフィールドです。 これにより、楽しいビデオチャットフィルター、モバイルデバイスのフェイスオーセンティケーター、自動運転車などのテクノロジーが強化されます。
このチュートリアルでは、コンピュータービジョンを使用して、Webカメラ用のアメリカ手話翻訳者を作成します。 チュートリアルを進めながら、 OpenCV 、コンピュータービジョンライブラリ、 PyTorch を使用してディープニューラルネットワークを構築し、onnxを使用して神経網。 また、コンピュータビジョンアプリケーションを構築するときに、次の概念を適用します。
- コンピュータービジョンを適用して感情ベースの犬のフィルターを作成する方法チュートリアルで使用したのと同じ3ステップの方法を使用します。データセットを前処理し、モデルをトレーニングし、モデルを評価します。
- また、これらの各ステップを拡張します。データ拡張を使用して回転または非中心の手に対処し、学習率スケジュールを変更してモデルの精度を向上させ、モデルをエクスポートして推論速度を高速化します。
- 途中で、機械学習の関連概念についても説明します。
このチュートリアルを終了すると、アメリカ手話翻訳者と基本的なディープラーニングのノウハウの両方を身に付けることができます。 このプロジェクトの完全なソースコードにアクセスすることもできます。
前提条件
このチュートリアルを完了するには、次のものが必要です。
- 1GB以上のRAMを搭載したPython3のローカル開発環境。 Python 3のローカルプログラミング環境をインストールおよびセットアップする方法に従って、必要なものをすべて構成できます。
- リアルタイムの画像検出を行うための動作するウェブカメラ。
- (推奨)感情ベースの犬用フィルターを作成する; このチュートリアルは明示的に使用されていませんが、同じアイデアが強化され、構築されています。
ステップ1—プロジェクトの作成と依存関係のインストール
このプロジェクトのワークスペースを作成し、必要な依存関係をインストールしましょう。
Linuxディストリビューションでは、まずシステムパッケージマネージャーを準備し、Python3virtualenvパッケージをインストールします。 使用する:
- apt-get update
- apt-get upgrade
- apt-get install python3-venv
ワークスペースをSignLanguageと呼びます。
- mkdir ~/SignLanguage
SignLanguageディレクトリに移動します。
- cd ~/SignLanguage
次に、プロジェクトの新しい仮想環境を作成します。
- python3 -m venv signlanguage
環境をアクティブ化します。
- source signlanguage/bin/activate
次に、このチュートリアルで使用するPythonのディープラーニングフレームワークであるPyTorchをインストールします。
macOSで、次のコマンドを使用してPytorchをインストールします。
- python -m pip install torch==1.2.0 torchvision==0.4.0
LinuxおよびWindowsでは、CPUのみのビルドに次のコマンドを使用します。
- pip install torch==1.2.0+cpu torchvision==0.4.0+cpu -f https://download.pytorch.org/whl/torch_stable.html
- pip install torchvision
次に、OpenCV、numpy、およびonnxのパッケージ済みバイナリをインストールします。これらは、それぞれコンピュータービジョン、線形代数、AIモデルのエクスポート、およびAIモデルの実行用のライブラリです。 OpenCVは画像の回転などのユーティリティを提供し、numpyは行列反転などの線形代数ユーティリティを提供します。
- python -m pip install opencv-python==3.4.3.18 numpy==1.14.5 onnx==1.6.0 onnxruntime==1.0.0
Linuxディストリビューションでは、libSM.soをインストールする必要があります。
- apt-get install libsm6 libxext6 libxrender-dev
依存関係をインストールしたら、手話翻訳者の最初のバージョンである手話分類子を作成しましょう。
ステップ2—手話分類データセットの準備
これらの次の3つのセクションでは、ニューラルネットワークを使用して手話分類器を構築します。 あなたの目標は、手の写真を入力として受け取り、文字を出力するモデルを作成することです。
機械学習分類モデルを構築するには、次の3つの手順が必要です。
- データの前処理:ワンホットエンコーディングをラベルに適用し、データをPyTorchTensorsでラップします。 拡張データでモデルをトレーニングして、中心から外れた手や回転した手のような「異常な」入力に備えます。
- モデルの指定とトレーニング:PyTorchを使用してニューラルネットワークを設定します。 トレーニングハイパーパラメータ(トレーニングの長さなど)を定義し、確率的勾配降下法を実行します。 また、学習率スケジュールである特定のトレーニングハイパーパラメータを変更します。 これらはモデルの精度を高めます。
- モデルを使用して予測を実行します。検証データでニューラルネットワークを評価して、その精度を理解します。 次に、モデルをONNXと呼ばれる形式にエクスポートして、推論速度を高速化します。
チュートリアルのこのセクションでは、ステップ1/3を実行します。 データをダウンロードし、Datasetオブジェクトを作成してデータを反復処理し、最後にデータ拡張を適用します。 このステップの最後に、データセット内の画像とラベルにアクセスしてモデルにフィードするプログラム的な方法があります。
まず、データセットを現在の作業ディレクトリにダウンロードします。
注:macOSでは、wgetはデフォルトでは使用できません。 これを行うには、このDigitalOceanチュートリアルに従ってHomebrewをインストールします。 次に、brew install wgetを実行します。
- wget https://assets.digitalocean.com/articles/signlanguage_data/sign-language-mnist.tar.gz
data/ディレクトリを含むzipファイルを解凍します。
- tar -xzf sign-language-mnist.tar.gz
step_2_dataset.pyという名前の新しいファイルを作成します。
- nano step_2_dataset.py
前と同じように、必要なユーティリティをインポートして、データを保持するクラスを作成します。 ここでのデータ処理では、トレインとテストのデータセットを作成します。 PyTorchのDatasetインターフェースを実装し、手話分類データセット用にPyTorchの組み込みデータパイプラインをロードして使用できるようにします。
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import numpy as np
import torch
import csv
class SignLanguageMNIST(Dataset):
"""Sign Language classification dataset.
Utility for loading Sign Language dataset into PyTorch. Dataset posted on
Kaggle in 2017, by an unnamed author with username `tecperson`:
https://www.kaggle.com/datamunge/sign-language-mnist
Each sample is 1 x 1 x 28 x 28, and each label is a scalar.
"""
pass
SignLanguageMNISTクラスのpassプレースホルダーを削除します。 その代わりに、ラベルマッピングを生成するメソッドを追加します。
@staticmethod
def get_label_mapping():
"""
We map all labels to [0, 23]. This mapping from dataset labels [0, 23]
to letter indices [0, 25] is returned below.
"""
mapping = list(range(25))
mapping.pop(9)
return mapping
ラベルの範囲は0〜25です。 ただし、文字J(9)およびZ(25)は除外されます。 これは、有効なラベル値が24個しかないことを意味します。 0から始まるすべてのラベル値のセットが連続するように、すべてのラベルを[0、23]にマップします。 データセットラベル[0、23]から文字インデックス[0、25]へのこのマッピングは、このget_label_mappingメソッドによって提供されます。
次に、CSVファイルからラベルとサンプルを抽出するメソッドを追加します。 以下は、各行がlabelで始まり、その後に784ピクセル値が続くことを前提としています。 これらの784ピクセル値は、28x28画像を表します。
@staticmethod
def read_label_samples_from_csv(path: str):
"""
Assumes first column in CSV is the label and subsequent 28^2 values
are image pixel values 0-255.
"""
mapping = SignLanguageMNIST.get_label_mapping()
labels, samples = [], []
with open(path) as f:
_ = next(f) # skip header
for line in csv.reader(f):
label = int(line[0])
labels.append(mapping.index(label))
samples.append(list(map(int, line[1:])))
return labels, samples
これらの784値が画像をどのように表すかについては、感情ベースの犬のフィルターの作成、ステップ4を参照してください。
csv.reader iterableの各行は、文字列のリストであることに注意してください。 intおよびmap(int, ...)の呼び出しは、すべての文字列を整数にキャストします。 静的メソッドのすぐ下に、データホルダーを初期化する関数を追加します。
def __init__(self,
path: str="data/sign_mnist_train.csv",
mean: List[float]=[0.485],
std: List[float]=[0.229]):
"""
Args:
path: Path to `.csv` file containing `label`, `pixel0`, `pixel1`...
"""
labels, samples = SignLanguageMNIST.read_label_samples_from_csv(path)
self._samples = np.array(samples, dtype=np.uint8).reshape((-1, 28, 28, 1))
self._labels = np.array(labels, dtype=np.uint8).reshape((-1, 1))
self._mean = mean
self._std = std
この関数は、サンプルとラベルをロードすることから始まります。 次に、データをNumPy配列にラップします。 平均と標準偏差の情報については、次の__getitem__セクションで簡単に説明します。
__init__関数の直後に、__len__関数を追加します。 Datasetでは、データの反復処理をいつ停止するかを決定するために、次のメソッドが必要です。
...
def __len__(self):
return len(self._labels)
最後に、__getitem__メソッドを追加します。このメソッドは、サンプルとラベルを含む辞書を返します。
def __getitem__(self, idx):
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomResizedCrop(28, scale=(0.8, 1.2)),
transforms.ToTensor(),
transforms.Normalize(mean=self._mean, std=self._std)])
return {
'image': transform(self._samples[idx]).float(),
'label': torch.from_numpy(self._labels[idx]).float()
}
データ拡張と呼ばれる手法を使用します。この手法では、トレーニング中にサンプルが摂動され、これらの摂動に対するモデルの堅牢性が向上します。 特に、RandomResizedCropを使用して、さまざまな量とさまざまな場所で画像をランダムに拡大します。 ズームインしても、最終的な手話クラスには影響しないことに注意してください。 したがって、ラベルは変換されません。 さらに、入力を正規化して、画像値が[0、255]ではなく[0、1]の範囲に再スケーリングされるようにします。 これを実現するには、正規化時にデータセット_meanおよび_stdを使用します。
完成したSignLanguageMNISTクラスは次のようになります。
from torch.utils.data import Dataset
from torch.autograd import Variable
import torchvision.transforms as transforms
import torch.nn as nn
import numpy as np
import torch
from typing import List
import csv
class SignLanguageMNIST(Dataset):
"""Sign Language classification dataset.
Utility for loading Sign Language dataset into PyTorch. Dataset posted on
Kaggle in 2017, by an unnamed author with username `tecperson`:
https://www.kaggle.com/datamunge/sign-language-mnist
Each sample is 1 x 1 x 28 x 28, and each label is a scalar.
"""
@staticmethod
def get_label_mapping():
"""
We map all labels to [0, 23]. This mapping from dataset labels [0, 23]
to letter indices [0, 25] is returned below.
"""
mapping = list(range(25))
mapping.pop(9)
return mapping
@staticmethod
def read_label_samples_from_csv(path: str):
"""
Assumes first column in CSV is the label and subsequent 28^2 values
are image pixel values 0-255.
"""
mapping = SignLanguageMNIST.get_label_mapping()
labels, samples = [], []
with open(path) as f:
_ = next(f) # skip header
for line in csv.reader(f):
label = int(line[0])
labels.append(mapping.index(label))
samples.append(list(map(int, line[1:])))
return labels, samples
def __init__(self,
path: str="data/sign_mnist_train.csv",
mean: List[float]=[0.485],
std: List[float]=[0.229]):
"""
Args:
path: Path to `.csv` file containing `label`, `pixel0`, `pixel1`...
"""
labels, samples = SignLanguageMNIST.read_label_samples_from_csv(path)
self._samples = np.array(samples, dtype=np.uint8).reshape((-1, 28, 28, 1))
self._labels = np.array(labels, dtype=np.uint8).reshape((-1, 1))
self._mean = mean
self._std = std
def __len__(self):
return len(self._labels)
def __getitem__(self, idx):
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomResizedCrop(28, scale=(0.8, 1.2)),
transforms.ToTensor(),
transforms.Normalize(mean=self._mean, std=self._std)])
return {
'image': transform(self._samples[idx]).float(),
'label': torch.from_numpy(self._labels[idx]).float()
}
前と同じように、SignLanguageMNISTデータセットをロードして、データセットユーティリティの機能を確認します。 SignLanguageMNISTクラスの後、ファイルの最後に次のコードを追加します。
def get_train_test_loaders(batch_size=32):
trainset = SignLanguageMNIST('data/sign_mnist_train.csv')
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True)
testset = SignLanguageMNIST('data/sign_mnist_test.csv')
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False)
return trainloader, testloader
このコードは、SignLanguageMNISTクラスを使用してデータセットを初期化します。 次に、トレインセットと検証セットの場合、データセットをDataLoaderでラップします。 これにより、データセットが後で使用できる反復可能に変換されます。
次に、データセットユーティリティが機能していることを確認します。 DataLoaderを使用してサンプルデータセットローダーを作成し、そのローダーの最初の要素を出力します。 ファイルの最後に以下を追加します。
if __name__ == '__main__':
loader, _ = get_train_test_loaders(2)
print(next(iter(loader)))
このファイル(リポジトリ)のstep_2_datasetファイルとファイルが一致していることを確認できます。 エディターを終了し、次のコマンドを使用してスクリプトを実行します。
- python step_2_dataset.py
これにより、次のテンソルのペアが出力されます。 データパイプラインは、2つのサンプルと2つのラベルを出力します。 これは、データパイプラインが稼働し、準備ができていることを示しています。
Output{'image': tensor([[[[ 0.4337, 0.5022, 0.5707, ..., 0.9988, 0.9646, 0.9646],
[ 0.4851, 0.5536, 0.6049, ..., 1.0502, 1.0159, 0.9988],
[ 0.5364, 0.6049, 0.6392, ..., 1.0844, 1.0844, 1.0673],
...,
[-0.5253, -0.4739, -0.4054, ..., 0.9474, 1.2557, 1.2385],
[-0.3369, -0.3369, -0.3369, ..., 0.0569, 1.3584, 1.3242],
[-0.3712, -0.3369, -0.3198, ..., 0.5364, 0.5364, 1.4783]]],
[[[ 0.2111, 0.2796, 0.3481, ..., 0.2453, -0.1314, -0.2342],
[ 0.2624, 0.3309, 0.3652, ..., -0.3883, -0.0629, -0.4568],
[ 0.3309, 0.3823, 0.4337, ..., -0.4054, -0.0458, -1.0048],
...,
[ 1.3242, 1.3584, 1.3927, ..., -0.4054, -0.4568, 0.0227],
[ 1.3242, 1.3927, 1.4612, ..., -0.1657, -0.6281, -0.0287],
[ 1.3242, 1.3927, 1.4440, ..., -0.4397, -0.6452, -0.2856]]]]), 'label': tensor([[24.],
[11.]])}
これで、データパイプラインが機能することを確認できました。 これで、最初のステップであるデータの前処理が完了しました。これには、モデルの堅牢性を高めるためのデータ拡張が含まれています。 次に、ニューラルネットワークとオプティマイザーを定義します。
ステップ3—ディープラーニングを使用した手話分類器の構築とトレーニング
データパイプラインが機能している状態で、モデルを定義し、データでトレーニングします。 特に、6層のニューラルネットワークを構築し、損失、オプティマイザーを定義し、最後に、ニューラルネットワーク予測の損失関数を最適化します。 このステップの最後に、手話分類子が機能するようになります。
step_3_train.pyという名前の新しいファイルを作成します。
- nano step_3_train.py
必要なユーティリティをインポートします。
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch
from step_2_dataset import get_train_test_loaders
3つの畳み込み層とそれに続く3つの完全に接続された層を含むPyTorchニューラルネットワークを定義します。 これを既存のスクリプトの最後に追加します。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 3)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 6, 3)
self.conv3 = nn.Conv2d(6, 16, 3)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 48)
self.fc3 = nn.Linear(48, 24)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
次に、ニューラルネットワークを初期化し、損失関数を定義し、スクリプトの最後に次のコードを追加して最適化ハイパーパラメーターを定義します。
def main():
net = Net().float()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
最後に、2つのエポックのトレーニングを行います。
def main():
net = Net().float()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
trainloader, _ = get_train_test_loaders()
for epoch in range(2): # loop over the dataset multiple times
train(net, criterion, optimizer, trainloader, epoch)
torch.save(net.state_dict(), "checkpoint.pth")
エポックを、すべてのトレーニングサンプルが1回だけ使用されたトレーニングの反復として定義します。 main関数の最後に、モデルパラメータが"checkpoint.pth"というファイルに保存されます。
スクリプトの最後に次のコードを追加して、データセットローダーからimageとlabelを抽出し、それぞれをPyTorchVariableでラップします。
def train(net, criterion, optimizer, trainloader, epoch):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs = Variable(data['image'].float())
labels = Variable(data['label'].long())
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels[:, 0])
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 100 == 0:
print('[%d, %5d] loss: %.6f' % (epoch, i, running_loss / (i + 1)))
このコードは、フォワードパスを実行してから、損失およびニューラルネットワークをバックプロパゲーションします。
ファイルの最後に、main関数を呼び出すために以下を追加します。
if __name__ == '__main__':
main()
ファイルが以下と一致することを再確認してください。
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch
from step_2_dataset import get_train_test_loaders
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 3)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 6, 3)
self.conv3 = nn.Conv2d(6, 16, 3)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 48)
self.fc3 = nn.Linear(48, 25)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def main():
net = Net().float()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
trainloader, _ = get_train_test_loaders()
for epoch in range(2): # loop over the dataset multiple times
train(net, criterion, optimizer, trainloader, epoch)
torch.save(net.state_dict(), "checkpoint.pth")
def train(net, criterion, optimizer, trainloader, epoch):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs = Variable(data['image'].float())
labels = Variable(data['label'].long())
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels[:, 0])
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 100 == 0:
print('[%d, %5d] loss: %.6f' % (epoch, i, running_loss / (i + 1)))
if __name__ == '__main__':
main()
保存して終了。 次に、次のコマンドを実行して、概念実証トレーニングを開始します。
- python step_3_train.py
ニューラルネットワークがトレーニングすると、次のような出力が表示されます。
Output[0, 0] loss: 3.208171
[0, 100] loss: 3.211070
[0, 200] loss: 3.192235
[0, 300] loss: 2.943867
[0, 400] loss: 2.569440
[0, 500] loss: 2.243283
[0, 600] loss: 1.986425
[0, 700] loss: 1.768090
[0, 800] loss: 1.587308
[1, 0] loss: 0.254097
[1, 100] loss: 0.208116
[1, 200] loss: 0.196270
[1, 300] loss: 0.183676
[1, 400] loss: 0.169824
[1, 500] loss: 0.157704
[1, 600] loss: 0.151408
[1, 700] loss: 0.136470
[1, 800] loss: 0.123326
より低い損失を得るには、エポックの数を5、10、または20に増やすことができます。 ただし、一定期間のトレーニング時間の後、ネットワーク損失はトレーニング時間の増加とともに減少しなくなります。 この問題を回避するために、トレーニング時間が長くなるにつれて、学習率スケジュールを導入します。これにより、時間の経過とともに学習率が低下します。 これが機能する理由を理解するには、「WhyMomentumReallyWorks」でのDistillの視覚化を参照してください。
main関数を次の2行で修正し、schedulerを定義してscheduler.stepを呼び出します。 さらに、エポック数を12に変更します。
def main():
net = Net().float()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
trainloader, _ = get_train_test_loaders()
for epoch in range(12): # loop over the dataset multiple times
train(net, criterion, optimizer, trainloader, epoch)
scheduler.step()
torch.save(net.state_dict(), "checkpoint.pth")
ファイルがこのリポジトリのステップ3ファイルと一致することを確認してください。 トレーニングは約5分間実行されます。 出力は次のようになります。
Output[0, 0] loss: 3.208171
[0, 100] loss: 3.211070
[0, 200] loss: 3.192235
[0, 300] loss: 2.943867
[0, 400] loss: 2.569440
[0, 500] loss: 2.243283
[0, 600] loss: 1.986425
[0, 700] loss: 1.768090
[0, 800] loss: 1.587308
...
[11, 0] loss: 0.000302
[11, 100] loss: 0.007548
[11, 200] loss: 0.009005
[11, 300] loss: 0.008193
[11, 400] loss: 0.007694
[11, 500] loss: 0.008509
[11, 600] loss: 0.008039
[11, 700] loss: 0.007524
[11, 800] loss: 0.007608
得られた最終損失は0.007608であり、開始損失3.20よりも3桁小さくなっています。 これでワークフローの2番目のステップが終了し、ニューラルネットワークをセットアップしてトレーニングします。 そうは言っても、この損失値が小さいとしても、それはほとんど意味がありません。 モデルのパフォーマンスを概観するために、モデルの精度、つまりモデルが正しく分類された画像のパーセンテージを計算します。
ステップ4—手話分類子の評価
次に、検証セットで精度を計算することにより、手話分類器を評価します。これは、モデルがトレーニング中に認識しなかった画像のセットです。 これにより、最終的な損失値よりもモデルのパフォーマンスが向上します。 さらに、トレーニングの最後にトレーニング済みモデルを保存し、推論を実行するときに事前トレーニング済みモデルをロードするユーティリティを追加します。
step_4_evaluate.pyという名前の新しいファイルを作成します。
- nano step_4_evaluate.py
必要なユーティリティをインポートします。
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch
import numpy as np
import onnx
import onnxruntime as ort
from step_2_dataset import get_train_test_loaders
from step_3_train import Net
次に、ニューラルネットワークのパフォーマンスを評価するユーティリティを定義します。 次の関数は、単一の画像について、ニューラルネットワークの予測された文字を実際の文字と比較します。
def evaluate(outputs: Variable, labels: Variable) -> float:
"""Evaluate neural network outputs against non-one-hotted labels."""
Y = labels.numpy()
Yhat = np.argmax(outputs, axis=1)
return float(np.sum(Yhat == Y))
outputsは、各サンプルのクラス確率のリストです。 たとえば、単一サンプルのoutputsは、[0.1, 0.3, 0.4, 0.2]の場合があります。 labelsはラベルクラスのリストです。 たとえば、ラベルクラスは3の場合があります。
Y = ...は、ラベルをNumPy配列に変換します。 次に、Yhat = np.argmax(...)は、outputsクラスの確率を予測クラスに変換します。 たとえば、クラス確率のリスト[0.1, 0.3, 0.4, 0.2]は、インデックス2の値0.4が最大値であるため、予測クラス2を生成します。
YとYhatの両方がクラスになっているので、それらを比較できます。 Yhat == Yは、予測されたクラスがラベルクラスと一致するかどうかをチェックし、np.sum(...)は、true-y値の数を計算するトリックです。 つまり、np.sumは、正しく分類されたサンプルの数を出力します。
2番目の関数batch_evaluateを追加します。これにより、最初の関数evaluateがすべての画像に適用されます。
def batch_evaluate(
net: Net,
dataloader: torch.utils.data.DataLoader) -> float:
"""Evaluate neural network in batches, if dataset is too large."""
score = n = 0.0
for batch in dataloader:
n += len(batch['image'])
outputs = net(batch['image'])
if isinstance(outputs, torch.Tensor):
outputs = outputs.detach().numpy()
score += evaluate(outputs, batch['label'][:, 0])
return score / n
batchは、単一のテンソルとして保存された画像のグループです。 まず、評価する画像の総数(n)を、このバッチ内の画像の数だけ増やします。 次に、この画像のバッチoutputs = net(...)を使用して、ニューラルネットワークで推論を実行します。 タイプチェックif isinstance(...)は、必要に応じて出力をNumPy配列に変換します。 最後に、evaluateを使用して、正しく分類されたサンプルの数を計算します。 関数の終わりに、正しく分類したサンプルのパーセントscore / nを計算します。
最後に、次のスクリプトを追加して、前述のユーティリティを活用します。
def validate():
trainloader, testloader = get_train_test_loaders()
net = Net().float()
pretrained_model = torch.load("checkpoint.pth")
net.load_state_dict(pretrained_model)
print('=' * 10, 'PyTorch', '=' * 10)
train_acc = batch_evaluate(net, trainloader) * 100.
print('Training accuracy: %.1f' % train_acc)
test_acc = batch_evaluate(net, testloader) * 100.
print('Validation accuracy: %.1f' % test_acc)
if __name__ == '__main__':
validate()
これにより、事前にトレーニングされたニューラルネットワークが読み込まれ、提供された手話データセットでのパフォーマンスが評価されます。 具体的には、ここでのスクリプトは、トレーニングに使用した画像と、テスト目的で取っておいた検証セットと呼ばれる別の画像セットの精度を出力します。
次に、PyTorchモデルをONNXバイナリにエクスポートします。 このバイナリファイルを本番環境で使用して、モデルで推論を実行できます。 最も重要なことは、このバイナリを実行するコードは、元のネットワーク定義のコピーを必要としないことです。 validate関数の最後に、以下を追加します。
trainloader, testloader = get_train_test_loaders(1)
# export to onnx
fname = "signlanguage.onnx"
dummy = torch.randn(1, 1, 28, 28)
torch.onnx.export(net, dummy, fname, input_names=['input'])
# check exported model
model = onnx.load(fname)
onnx.checker.check_model(model) # check model is well-formed
# create runnable session with exported model
ort_session = ort.InferenceSession(fname)
net = lambda inp: ort_session.run(None, {'input': inp.data.numpy()})[0]
print('=' * 10, 'ONNX', '=' * 10)
train_acc = batch_evaluate(net, trainloader) * 100.
print('Training accuracy: %.1f' % train_acc)
test_acc = batch_evaluate(net, testloader) * 100.
print('Validation accuracy: %.1f' % test_acc)
これにより、ONNXモデルがエクスポートされ、エクスポートされたモデルがチェックされてから、エクスポートされたモデルで推論が実行されます。 ファイルがこのリポジトリのステップ4ファイルと一致することを再確認してください。
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch
import numpy as np
import onnx
import onnxruntime as ort
from step_2_dataset import get_train_test_loaders
from step_3_train import Net
def evaluate(outputs: Variable, labels: Variable) -> float:
"""Evaluate neural network outputs against non-one-hotted labels."""
Y = labels.numpy()
Yhat = np.argmax(outputs, axis=1)
return float(np.sum(Yhat == Y))
def batch_evaluate(
net: Net,
dataloader: torch.utils.data.DataLoader) -> float:
"""Evaluate neural network in batches, if dataset is too large."""
score = n = 0.0
for batch in dataloader:
n += len(batch['image'])
outputs = net(batch['image'])
if isinstance(outputs, torch.Tensor):
outputs = outputs.detach().numpy()
score += evaluate(outputs, batch['label'][:, 0])
return score / n
def validate():
trainloader, testloader = get_train_test_loaders()
net = Net().float().eval()
pretrained_model = torch.load("checkpoint.pth")
net.load_state_dict(pretrained_model)
print('=' * 10, 'PyTorch', '=' * 10)
train_acc = batch_evaluate(net, trainloader) * 100.
print('Training accuracy: %.1f' % train_acc)
test_acc = batch_evaluate(net, testloader) * 100.
print('Validation accuracy: %.1f' % test_acc)
trainloader, testloader = get_train_test_loaders(1)
# export to onnx
fname = "signlanguage.onnx"
dummy = torch.randn(1, 1, 28, 28)
torch.onnx.export(net, dummy, fname, input_names=['input'])
# check exported model
model = onnx.load(fname)
onnx.checker.check_model(model) # check model is well-formed
# create runnable session with exported model
ort_session = ort.InferenceSession(fname)
net = lambda inp: ort_session.run(None, {'input': inp.data.numpy()})[0]
print('=' * 10, 'ONNX', '=' * 10)
train_acc = batch_evaluate(net, trainloader) * 100.
print('Training accuracy: %.1f' % train_acc)
test_acc = batch_evaluate(net, testloader) * 100.
print('Validation accuracy: %.1f' % test_acc)
if __name__ == '__main__':
validate()
最後のステップのチェックポイントを使用して評価するには、次のコマンドを実行します。
- python step_4_evaluate.py
これにより、次のような出力が生成され、エクスポートされたモデルが機能するだけでなく、元のPyTorchモデルとも一致することが確認されます。
Output========== PyTorch ==========
Training accuracy: 99.9
Validation accuracy: 97.4
========== ONNX ==========
Training accuracy: 99.9
Validation accuracy: 97.4
ニューラルネットワークは、99.9%のトレイン精度と97.4%の検証精度を達成します。 トレインと検証の精度の間のこのギャップは、モデルが過剰適合であることを示しています。 これは、一般化可能なパターンを学習する代わりに、モデルがトレーニングデータを記憶していることを意味します。 過剰適合の影響と原因を理解するには、偏りと分散のトレードオフについてを参照してください。
この時点で、手話分類子が完成しました。 本質的に、私たちのモデルは、ほとんどの場合、標識間を正しく明確にすることができます。 これはかなり良いモデルなので、アプリケーションの最終段階に進みます。 この手話分類子をリアルタイムWebカメラアプリケーションで使用します。
ステップ5—カメラフィードをリンクする
次の目的は、コンピューターのカメラを手話分類子にリンクすることです。 カメラ入力を収集し、表示された手話を分類してから、分類された手話をユーザーに報告します。
次に、顔検出器用のPythonスクリプトを作成します。 nanoまたはお気に入りのテキストエディタを使用して、ファイルstep_6_camera.pyを作成します。
- nano step_5_camera.py
次のコードをファイルに追加します。
"""Test for sign language classification"""
import cv2
import numpy as np
import onnxruntime as ort
def main():
pass
if __name__ == '__main__':
main()
このコードは、画像ユーティリティを含むOpenCVと、モデルで推論を実行するために必要なすべてのONNXランタイムをインポートします。 残りのコードは、典型的なPythonプログラムの定型文です。
次に、main関数のpassを次のコードに置き換えます。このコードは、以前にトレーニングしたパラメーターを使用して手話分類子を初期化します。 さらに、インデックスから文字および画像統計へのマッピングを追加します。
def main():
# constants
index_to_letter = list('ABCDEFGHIKLMNOPQRSTUVWXY')
mean = 0.485 * 255.
std = 0.229 * 255.
# create runnable session with exported model
ort_session = ort.InferenceSession("signlanguage.onnx")
このテストスクリプトの要素は、OpenCVの公式ドキュメントから使用します。 具体的には、main関数の本体を更新します。 コンピューターのカメラからライブフィードをキャプチャするように設定されているVideoCaptureオブジェクトを初期化することから始めます。 これをmain関数の最後に配置します。
def main():
...
# create runnable session with exported model
ort_session = ort.InferenceSession("signlanguage.onnx")
cap = cv2.VideoCapture(0)
次に、whileループを追加します。このループは、すべてのタイムステップでカメラから読み取ります。
def main():
...
cap = cv2.VideoCapture(0)
while True:
# Capture frame-by-frame
ret, frame = cap.read()
カメラフレームの中央の切り抜きを取得するユーティリティ関数を記述します。 この関数をmainの前に配置します。
def center_crop(frame):
h, w, _ = frame.shape
start = abs(h - w) // 2
if h > w:
frame = frame[start: start + w]
else:
frame = frame[:, start: start + h]
return frame
次に、カメラフレームの中央の切り抜きを取り、グレースケールに変換し、正規化し、28x28にサイズ変更します。 これをmain関数内のwhileループ内に配置します。
def main():
...
while True:
# Capture frame-by-frame
ret, frame = cap.read()
# preprocess data
frame = center_crop(frame)
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY)
x = cv2.resize(frame, (28, 28))
x = (frame - mean) / std
引き続きwhileループ内で、ONNXランタイムを使用して推論を実行します。 出力をクラスインデックスに変換してから、文字に変換します。
...
x = (frame - mean) / std
x = x.reshape(1, 1, 28, 28).astype(np.float32)
y = ort_session.run(None, {'input': x})[0]
index = np.argmax(y, axis=1)
letter = index_to_letter[int(index)]
フレーム内に予測された文字を表示し、フレームをユーザーに表示します。
...
letter = index_to_letter[int(index)]
cv2.putText(frame, letter, (100, 100), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (0, 255, 0), thickness=2)
cv2.imshow("Sign Language Translator", frame)
whileループの最後に、このコードを追加して、ユーザーがq文字をヒットしたかどうかを確認し、ヒットした場合はアプリケーションを終了します。 この行は、プログラムを1ミリ秒停止します。 以下を追加します。
...
cv2.imshow("Sign Language Translator", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
最後に、キャプチャを解放して、すべてのウィンドウを閉じます。 これをwhileループの外側に配置して、main機能を終了します。
...
while True:
...
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
ファイルが次またはこのリポジトリと一致することを再確認してください。
import cv2
import numpy as np
import onnxruntime as ort
def center_crop(frame):
h, w, _ = frame.shape
start = abs(h - w) // 2
if h > w:
return frame[start: start + w]
return frame[:, start: start + h]
def main():
# constants
index_to_letter = list('ABCDEFGHIKLMNOPQRSTUVWXY')
mean = 0.485 * 255.
std = 0.229 * 255.
# create runnable session with exported model
ort_session = ort.InferenceSession("signlanguage.onnx")
cap = cv2.VideoCapture(0)
while True:
# Capture frame-by-frame
ret, frame = cap.read()
# preprocess data
frame = center_crop(frame)
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY)
x = cv2.resize(frame, (28, 28))
x = (x - mean) / std
x = x.reshape(1, 1, 28, 28).astype(np.float32)
y = ort_session.run(None, {'input': x})[0]
index = np.argmax(y, axis=1)
letter = index_to_letter[int(index)]
cv2.putText(frame, letter, (100, 100), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (0, 255, 0), thickness=2)
cv2.imshow("Sign Language Translator", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
main()
ファイルを終了し、スクリプトを実行します。
- python step_5_camera.py
スクリプトが実行されると、ライブWebカメラフィードを含むウィンドウがポップアップ表示されます。 予測される手話文字が左上に表示されます。 手をかざしてお気に入りのサインを作成し、分類器の動作を確認します。 これは、文字LおよびDを示すいくつかのサンプル結果です。

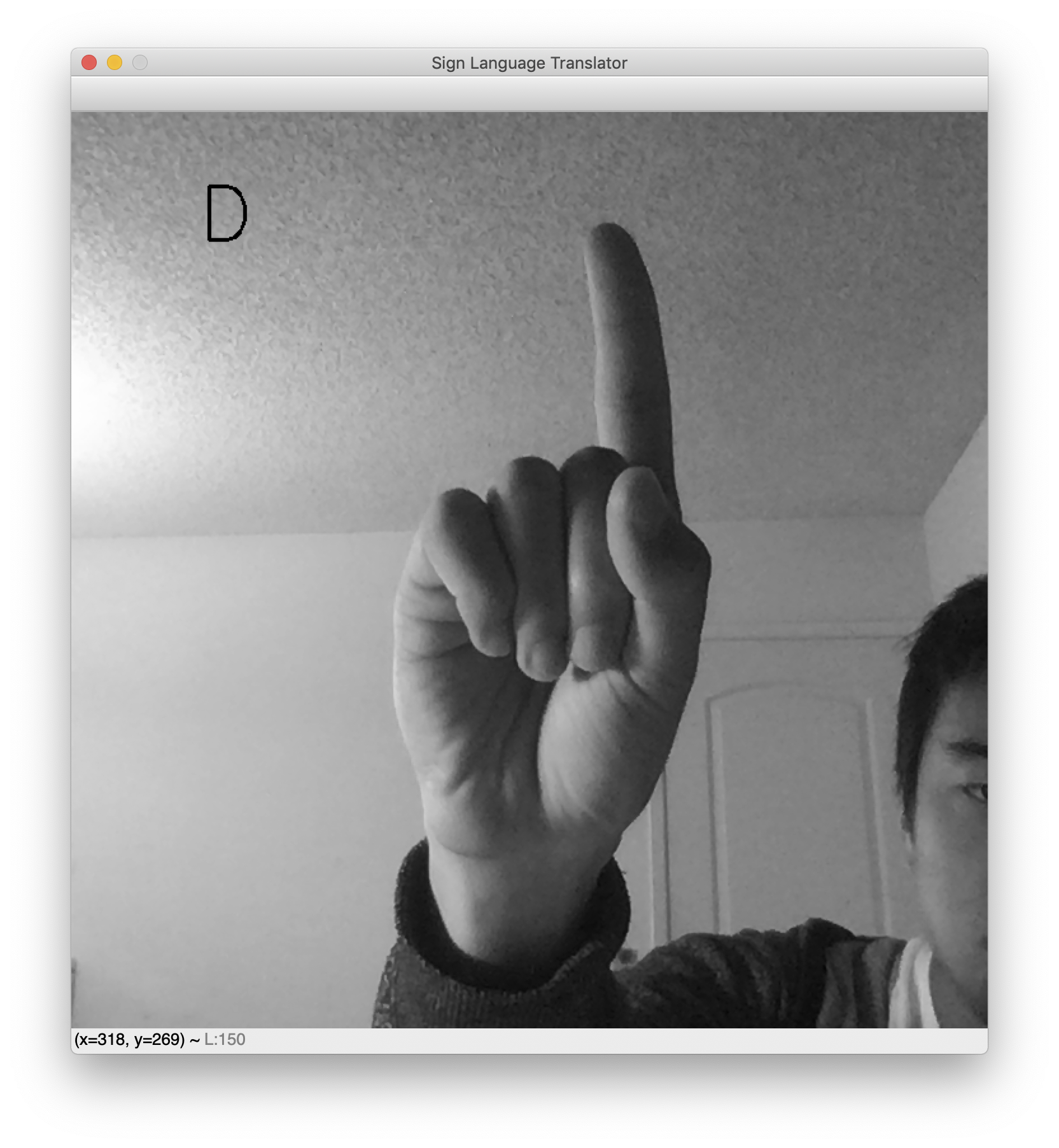
テスト中、この翻訳者が機能するには、背景がかなり明確である必要があることに注意してください。 これは、データセットのクリーンさの不幸な結果です。 データセットにさまざまな背景の手のサインの画像が含まれていれば、ネットワークはノイズの多い背景に対して堅牢になります。 ただし、データセットは空白の背景と適切に中央に配置された手を備えています。 結果として、このWebカメラトランスレータは、手が同様に中央に配置され、空白の背景に配置されている場合に最適に機能します。
これで手話通訳アプリケーションは終了です。
結論
このチュートリアルでは、コンピュータービジョンと機械学習モデルを使用してアメリカ手話翻訳者を作成しました。 特に、機械学習モデルのトレーニングの新しい側面、具体的には、モデルの堅牢性のためのデータ拡張、低損失のための学習率スケジュール、およびONNXを使用したAIモデルの本番環境へのエクスポートについて説明しました。 これは、構築したパイプラインを使用して手話を文字に変換するリアルタイムのコンピュータービジョンアプリケーションで最高潮に達しました。 最終的な分類器の脆弱性と戦うことは、以下の方法のいずれかまたはすべてで取り組むことができることに注意する価値があります。 さらに詳しく調べるには、次のトピックを試して、アプリケーションを改善してください。
- 一般化:これはコンピュータービジョン内のサブトピックではなく、機械学習全体を通じて常に問題になっています。 偏りと分散のトレードオフについてを参照してください。
- ドメインの適応:モデルがドメインAでトレーニングされているとします(たとえば、日当たりの良い環境)。 モデルをドメインB(たとえば、曇りの環境)にすばやく適応させることができますか?
- 敵対者の例:敵対者がモデルをだますために意図的に画像を設計しているとしましょう。 そのような画像をどのようにデザインできますか? どうすればそのような画像と戦うことができますか?