序章
MySQLクラスターは、高可用性とスループットを提供するソフトウェアテクノロジーです。 他のクラスターテクノロジーに既に精通している場合は、それらに類似したMySQLクラスターが見つかります。 つまり、データノード(データが保存される場所)を制御する1つ以上の管理ノードがあります。 管理ノードと相談した後、クライアント(MySQLクライアント、サーバー、またはネイティブAPI)はデータノードに直接接続します。
MySQLレプリケーションがMySQLクラスターにどのように関連しているか疑問に思われるかもしれません。 クラスタでは、データの一般的なレプリケーションはありませんが、代わりにデータノードの同期があります。 この目的のために、特別なデータエンジンを使用する必要があります— NDBCluster(NDB)。 クラスタは、冗長コンポーネントを備えた単一の論理MySQL環境と考えてください。 したがって、MySQLクラスターは他のMySQLクラスターとのレプリケーションに参加できます。
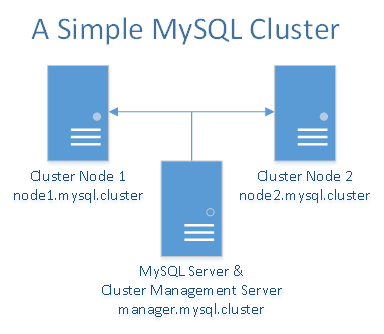
MySQLクラスターは、シェアードナッシング環境で最適に動作します。 理想的には、2つのコンポーネントが同じハードウェアを共有しないようにする必要があります。 簡単にするため、およびデモンストレーションの目的で、3つのドロップレットのみを使用するように制限します。 それらの間でデータを同期しているデータノードとして機能する2つのドロップレットがあります。 3番目のドロップレットは、クラスターマネージャーに使用されると同時に、MySQLサーバー/クライアントにも使用されます。 ドロップレットがさらにある場合は、データノードを追加したり、クラスターマネージャーをMySQLサーバー/クライアントから分離したり、クラスターマネージャーおよびMySQLサーバー/クライアントとしてドロップレットを追加したりすることもできます。

前提条件
合計3つのドロップレットが必要になります。MySQLクラスターマネージャーとMySQLサーバー/クライアント用に1つのドロップレット、冗長MySQLデータノード用に2つのドロップレットです。
同じDigitalOceanデータセンターで、プライベートネットワークを有効にしたで次のドロップレットを作成します。
- 最小1GBのRAMとプライベートネットワークが有効になっている3つのUbuntu16.04ドロップレット
- 各ドロップレットのsudo権限を持つroot以外のユーザー( Ubuntu 16.04 を使用した初期サーバーセットアップでは、これをセットアップする方法について説明しています)。
MySQLクラスターはRAMに多くの情報を保存します。 各ドロップレットには、少なくとも1GBのRAMが必要です。
プライベートネットワークチュートリアルで説明したように、必ず3つのドロップレットのカスタムレコードを設定してください。 わかりやすく便利にするために、/etc/hostsファイルの各ドロップレットに次のカスタムレコードを使用します。
10.XXX.XX.X node1.mysql.cluster 10.YYY.YY.Y node2.mysql.cluster 10.ZZZ.ZZ.Zマネージャー.mysql.cluster
強調表示されたIPを、それに応じてドロップレットのプライベートIPに置き換えてください。
特に明記されていない限り、このチュートリアルでroot権限を必要とするすべてのコマンドは、sudo権限を持つroot以外のユーザーとして実行する必要があります。
ステップ1—MySQLクラスターのダウンロードとインストール
このチュートリアルを書いている時点では、MySQLクラスターの最新のGPLバージョンは7.4.11です。 この製品はMySQL5.6の上に構築されており、次のものが含まれます。
- クラスタマネージャソフトウェア
- データノードマネージャーソフトウェア
- MySQL5.6サーバーおよびクライアントバイナリ
無料の一般提供(GA)MySQLクラスターリリースは、公式MySQLクラスターダウンロードページからダウンロードできます。 このページから、Ubuntuにも適したDebianLinuxプラットフォームパッケージを選択します。 また、ドロップレットのアーキテクチャに応じて、32ビットまたは64ビットバージョンを選択してください。 インストールパッケージを各ドロップレットにアップロードします。
インストール手順はすべてのドロップレットで同じであるため、3つのドロップレットすべてでこれらの手順を実行します。
インストールを開始する前に、libaio1パッケージをインストールする必要があります。これは、依存関係であるためです。
- sudo apt-get install libaio1
その後、MySQLクラスターパッケージをインストールします。
- sudo dpkg -i mysql-cluster-gpl-7.4.11-debian7-x86_64.deb
これで、MySQLクラスターのインストールがディレクトリ/opt/mysql/server-5.6/にあります。 特に、すべてのバイナリが存在するbinディレクトリ(/opt/mysql/server-5.6/bin/)を使用します。
それぞれが異なる機能(マネージャーまたはデータノード)を持っているという事実に関係なく、3つのドロップレットすべてで同じインストール手順を実行する必要があります。
次に、各ドロップレットでMySQLクラスターマネージャーを構成します。
ステップ2—クラスタマネージャの設定と起動
このステップでは、MySQLクラスターマネージャー(manager.mysql.cluster)を構成します。 その適切な構成により、データノード間の正しい同期と負荷分散が保証されます。 すべてのコマンドは、Dropletmanager.mysql.clusterで実行する必要があります。
クラスタマネージャは、任意のクラスタで起動する必要がある最初のコンポーネントです。 バイナリファイルに引数として渡される構成ファイルが必要です。 便宜上、ファイル/var/lib/mysql-cluster/config.iniを構成に使用します。
manager.mysql.clusterドロップレットで、最初にこのファイルが存在するディレクトリ(/var/lib/mysql-cluster)を作成します。
- sudo mkdir /var/lib/mysql-cluster
次に、ファイルを作成し、nanoで編集を開始します。
- sudo nano /var/lib/mysql-cluster/config.ini
このファイルには、次のコードが含まれている必要があります。
[ndb_mgmd]
# Management process options:
hostname=manager.mysql.cluster # Hostname of the manager
datadir=/var/lib/mysql-cluster # Directory for the log files
[ndbd]
hostname=node1.mysql.cluster # Hostname of the first data node
datadir=/usr/local/mysql/data # Remote directory for the data files
[ndbd]
hostname=node2.mysql.cluster # Hostname of the second data node
datadir=/usr/local/mysql/data # Remote directory for the data files
[mysqld]
# SQL node options:
hostname=manager.mysql.cluster # In our case the MySQL server/client is on the same Droplet as the cluster manager
上記の各コンポーネントに対して、hostnameパラメーターを定義しました。 指定されたホスト名のみがマネージャーに接続し、指定された役割に従ってクラスターに参加できるため、これは重要なセキュリティ対策です。
さらに、hostnameパラメーターは、サービスを実行するインターフェースを指定します。 この場合、上記のホスト名は/etc/hostsファイルで指定したプライベートIPを指しているため、これは重要であり、セキュリティにとって重要です。 したがって、プライベートネットワークの外部から上記のサービスにアクセスすることはできません。
上記のファイルでは、まったく同じ方法で追加のインスタンスを定義するだけで、データノード(ndbd)やMySQLサーバー(mysqld)などの冗長コンポーネントを追加できます。
これで、ndb_mgmdバイナリを実行し、次のように-f引数を指定して構成ファイルを指定することにより、マネージャーを初めて起動できます。
- sudo /opt/mysql/server-5.6/bin/ndb_mgmd -f /var/lib/mysql-cluster/config.ini
次のような正常な起動に関するメッセージが表示されます。
Output of ndb_mgmdMySQL Cluster Management Server mysql-5.6.29 ndb-7.4.11
サーバーで管理サービスを自動的に開始することをお勧めします。 GAクラスターリリースには適切な起動スクリプトが付属していませんが、オンラインで利用できるものがいくつかあります。 まず、startコマンドを/etc/rc.localファイルに追加するだけで、起動時にサービスが自動的に開始されます。 ただし、最初に、サーバーの起動時に/etc/rc.localが実行されていることを確認する必要があります。 Ubuntu 16.04では、これには追加のコマンドを実行する必要があります。
- sudo systemctl enable rc-local.service
次に、ファイル/etc/rc.localを開いて編集します。
- sudo nano /etc/rc.local
次のように、exit行の前に開始コマンドを追加します。
...
/opt/mysql/server-5.6/bin/ndb_mgmd -f /var/lib/mysql-cluster/config.ini
exit 0
ファイルを保存して終了します。
クラスタマネージャは常に実行する必要はありません。 クラスターのダウンタイムなしで、開始、停止、および再起動できます。 これは、クラスターノードとMySQLサーバー/クライアントの初期起動時にのみ必要です。
ステップ3—データノードの構成と開始
次に、データファイルを保存してNDBエンジンを適切にサポートするように、データノード(node1.mysql.clusterおよびnode2.mysql.cluster)を構成します。 すべてのコマンドは、両方のノードで実行する必要があります。 最初にnode1.mysql.clusterから始めて、node2.mysql.clusterでまったく同じ手順を繰り返すことができます。
データノードは、標準のMySQL構成ファイル/etc/my.cnfから構成を読み取り、より具体的には[mysql_cluster]行の後の部分を読み取ります。 nanoでこのファイルを作成し、編集を開始します。
- sudo nano /etc/my.cnf
次のようにマネージャのホスト名を指定します。
[mysql_cluster]
ndb-connectstring=manager.mysql.cluster
ファイルを保存して終了します。
マネージャーの場所を指定することは、ノードエンジンを起動するために必要な唯一の構成です。 残りの構成は、マネージャーから直接取得されます。 この例では、データノードは、マネージャーの構成に従って、そのデータディレクトリが/usr/local/mysql/dataであることを確認します。 このディレクトリはノード上に作成する必要があります。 次のコマンドで実行できます。
- sudo mkdir -p /usr/local/mysql/data
その後、次のコマンドを使用してデータノードを初めて起動できます。
- sudo /opt/mysql/server-5.6/bin/ndbd
正常に起動すると、同様の出力が表示されます。
Output of ndbd2016-05-11 16:12:23 [ndbd] INFO -- Angel connected to 'manager.mysql.cluster:1186'
2016-05-11 16:12:23 [ndbd] INFO -- Angel allocated nodeid: 2
ndbdサービスをサーバーで自動的に開始する必要があります。 GAクラスターリリースには、これに適した起動スクリプトも付属していません。 クラスタマネージャの場合と同じように、/etc/rc.localファイルにスタートアップコマンドを追加しましょう。 ここでも、次のコマンドを使用して、サーバーの起動中に/etc/rc.localが実行されていることを確認する必要があります。
- sudo systemctl enable rc-local.service
次に、ファイル/etc/rc.localを開いて編集します。
- sudo nano /etc/rc.local
次のように、exit行の前に開始コマンドを追加します。
...
/opt/mysql/server-5.6/bin/ndbd
exit 0
ファイルを保存して終了します。
最初のノードで終了したら、他のノード(この例ではnode2.mysql.cluster)でまったく同じ手順を繰り返します。
ステップ4—MySQLサーバーとクライアントの構成と起動
Ubuntuのデフォルトのaptリポジトリで利用できるような標準のMySQLサーバーは、MySQLクラスターエンジンNDBをサポートしていません。 そのため、カスタムMySQLサーバーをインストールする必要があります。 3つのドロップレットにすでにインストールされているクラスターパッケージには、MySQLサーバーとクライアントも付属しています。 すでに述べたように、管理ノード(manager.mysql.cluster)でMySQLサーバーとクライアントを使用します。
構成は、デフォルトの/etc/my.cnfファイルに再度保存されます。 manager.mysql.clusterで、構成ファイルを開きます。
sudo nano /etc/my.cnf
次に、それに以下を追加します。
[mysqld]
ndbcluster # run NDB storage engine
...
ファイルを保存して終了します。
ベストプラクティスに従って、MySQLサーバーは、独自のグループ(mysql)に属する独自のユーザー(mysql)で実行する必要があります。 それでは、最初にグループを作成しましょう。
- sudo groupadd mysql
次に、このグループに属するmysqlユーザーを作成し、次のようにシェルパスを/bin/falseに設定して、シェルを使用できないことを確認します。
- sudo useradd -r -g mysql -s /bin/false mysql
カスタムMySQLサーバーをインストールするための最後の要件は、デフォルトのデータベースを作成することです。 次のコマンドで実行できます。
- sudo /opt/mysql/server-5.6/scripts/mysql_install_db --user=mysql
MySQLサーバーの起動には、/opt/mysql/server-5.6/support-files/mysql.serverの起動スクリプトを使用します。 次のように、mysqldという名前でデフォルトのinitscriptsディレクトリにコピーします。
- sudo cp /opt/mysql/server-5.6/support-files/mysql.server /etc/init.d/mysqld
起動スクリプトを有効にし、次のコマンドを使用してデフォルトのランレベルに追加します。
- sudo systemctl enable mysqld.service
これで、次のコマンドを使用して、MySQLサーバーを初めて手動で起動できます。
- sudo systemctl start mysqld
MySQLクライアントとして、クラスターのインストールに付属するカスタムバイナリを再度使用します。 次のパスがあります:/opt/mysql/server-5.6/bin/mysql。 便宜上、デフォルトの/usr/binパスにシンボリックリンクを作成しましょう。
- sudo ln -s /opt/mysql/server-5.6/bin/mysql /usr/bin/
これで、次のようにmysqlと入力するだけで、コマンドラインからクライアントを起動できます。
- mysql
次のような出力が表示されます。
Output of ndb_mgmdWelcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3
Server version: 5.6.29-ndb-7.4.11-cluster-gpl MySQL Cluster Community Server (GPL)
MySQLプロンプトを終了するには、quitと入力するか、CTRL-Dを同時に押します。
上記は、MySQLクラスター、サーバー、およびクライアントが機能していることを示す最初のチェックです。 次に、クラスターが正しく機能していることを確認するために、より詳細なテストを実行します。
クラスターのテスト
この時点で、1つのクライアント、1つのサーバー、1つのマネージャー、および2つのデータノードを備えた単純なMySQLクラスターが完成するはずです。 クラスタマネージャのドロップレット(manager.mysql.cluster)から、次のコマンドで管理コンソールを開きます。
- sudo /opt/mysql/server-5.6/bin/ndb_mgm
これで、プロンプトがクラスター管理コンソールに変わります。 次のようになります。
Inside the ndb_mgm console-- NDB Cluster -- Management Client --
ndb_mgm>
コンソール内に入ると、次のようにコマンドSHOWを実行します。
- SHOW
次のような出力が表示されます。
Output of ndb_mgmConnected to Management Server at: manager.mysql.cluster:1186
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=2 @10.135.27.42 (mysql-5.6.29 ndb-7.4.11, Nodegroup: 0, *)
id=3 @10.135.27.43 (mysql-5.6.29 ndb-7.4.11, Nodegroup: 0)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @10.135.27.51 (mysql-5.6.29 ndb-7.4.11)
[mysqld(API)] 1 node(s)
id=4 @10.135.27.51 (mysql-5.6.29 ndb-7.4.11)
上記は、IDが2と3の2つのデータノードがあることを示しています。 それらはアクティブで接続されています。 ID1の管理ノードとID4のMySQLサーバーも1つあります。 次のようにコマンドSTATUSを使用して番号を入力すると、各IDの詳細を確認できます。
- 2 STATUS
- ``
- `
-
The above command would show you the status of node 2 along with its MySQL and NDB versions:
-
- ```
- [secondary_label Output of ndb_mgm]
- Node 2: started (mysql-5.6.29 ndb-7.4.11)
- ``
- `
-
To exit the management console type `quit- `.
-
The management console is very powerful and gives you many other options - for managing the cluster and its data, including creating an online backup. For more information check the [official documentation](http://dev.mysql.com/doc/refman/5.6/en/mysql-cluster-management.html "here").
-
Let's have a test with the MySQL client now. From the same Droplet, start the client with the `mysql` command for the MySQL root user. Please recall that we have created a symlink to it earlier.
-
- ```command
- mysql -u root
- ```
-
- \Your console will change to the MySQL client console. Once inside the MySQL client, run the command:
-
- ``
- `custom_prefix(mysql>)
SHOW ENGINE NDB STATUS
\G
- ```
-
- Now you should see all the information about the NDB cluster engine starting with the connection details:
-
- ```
- [secondary_label Output of mysql]
-
- *************************** 1. row ***************************
- Type: ndbcluster
- Name: connection
- Status: cluster_node_id=4, connected_host=manager.mysql.cluster, connected_port=1186, number_of_data_nodes=2, number_of_ready_data_nodes=2, connect_count=0
- ...
- ``
- `
-
The - most important information from above is the number of ready nodes — 2. This redundancy will allow your MySQL cluster to continue operating even if one of the data nodes fails while. At the same time your SQL queries will be load balanced to the two nodes.
-
You can try shutting down one of the data nodes in order to test the cluster stability. The simplest thing would be just to restart the whole Droplet in order to have a full test of the recovery process. You will see the value of `number_of_ready_data_nodes` change to `1` and back to `2` again as the node is restarted.
-
- ### Working with the NDB Engine
-
- To see how the cluster really works, let
- 's create a new table with the NDB engine and insert some data into it. Please note that in order to use the cluster functionality, the engine must be NDB. If you use InnoDB (default) or any other engine other than NDB, you will not make use of the cluster.
-
First, let' s create a database called `cluster` with the command:
-
- ``
- `custom_prefix(mysql>)
CREATE DATABASE cluster
;
- ```
-
- Next, switch to the new database:
-
- ``
- `custom_prefix(mysql>)
USE cluster
;
- ``
- `
-
Now, create a simple table called `cluster_test` like this:
-
- ``
- `custom_prefix(mysql>)
CREATE TABLE cluster_test
(name VARCHAR(20), value VARCHAR(20)) ENGINE=ndbcluster;
- ``
- `
-
We have explicitly specified above the engine `ndbcluster` in order to make use of the cluster. Next, we can start inserting data with a query like this:
-
- ``
- `custom_prefix(mysql>)
INSERT INTO cluster_test
(name,value) VALUES('some_name','some_value');
- ``
- `
-
To verify the data has been inserted, run a select query like this:
-
- ``
- `custom_prefix(mysql>)
SELECT * FROM cluster_test
;
- ```
-
- When you are inserting and selecting data like this, you are load-balancing your queries between all the available data node, which are two in our example. With this scaling out you benefit both in terms of stability and performance.
-
- ## Conclusion
-
- As we have seen in this article, setting up a MySQL cluster can be simple and easy. Of course, there are many more advanced options and features which are worth mastering before bringing the cluster to your production environment. As always, make sure to have an adequate testing process because some problems could be very hard to solve later. For more information and further reading please go to the official documentation for [MySQL cluster](http://dev.mysql.com/doc/refman/5.6/en/mysql-cluster.html).
