Ubuntu16.04の3ノードクラスターにCockroachDBをデプロイする方法
CockroachDBからの記事
序章
CockroachDBは、一貫性、スケーラビリティ、および存続可能性を提供するオープンソースの分散SQLデータベースです。
CockroachDBの設定は簡単です。それぞれがノードと呼ばれる複数のサーバーにインストールし、それらを結合して、クラスターと呼ばれる単一のエンティティであるかのように機能します。 クラスタ内のすべてのノードは対称的に動作し、同じデータにアクセスできます。
この種の設計では、データストレージのニーズが増大するにつれて、新しいノードを作成して既存のクラスターに参加させることで、システムの容量を簡単に増やすことができます。 詳細については、CockroachDBのスケーラビリティモデルを参照してください。
注:執筆時点では、CockroachDBは現在 beta であるため、このガイドは、作品の展開ガイドとしてではなく、テクノロジーに慣れるための機会として使用することをお勧めします。ミッションクリティカルなソフトウェアの。
このガイドでは、クラスターの管理UIへのアクセスを保護していません。 正しいURLを知っていれば、誰でもアクセスできます。 これを本番環境に残す場合は、ファイアウォールルールを使用してポート8080へのアクセスを制御することを検討してください。
目標
このガイドでは、CockroachDBを複数のサーバー(分散マルチノードクラスター)にデプロイすることにより、分散型でフォールトトレラントなデータベースを作成します。 まず、CockroachDBを複数のサーバーにインストールし、それらをノードとして起動してから、クラスターとして連携させます。
さらに、データの分散と、クラスターが障害に耐える方法を示し、アプリケーションをCockroachDBに接続する方法を示します。
このガイドでは、SSL暗号化を使用しない安全でない展開の設定について説明します。これは、本番環境にはお勧めしません。 ただし、CockroachDBは、DigitalOceanの安全な展開手順も提供します。 (リンクの最初の段落に書かれていることにもかかわらず、記事の Secure バージョンが選択されています。)
前提条件
始める前に、次のものが必要です。
- プライベートネットワークが有効になっているで少なくとも2GBのRAMを備えた3つのUbuntu16.04サーバー。 それらはすべて同じ地域にある必要があります。 このガイドでは、次のホスト名を使用します。
- cockroach-01 cockroach-02 cockroach-03
- 各サーバーで、sudo権限を持つroot以外のユーザーを追加します
- 次のポートでTCPトラフィックが許可されていることを確認してください。 ファイアウォールとしてUFWを設定している場合、各サーバーで次の2つのポートを許可する必要があります:
- ノード間およびアプリケーション通信用の26257:sudoufwは管理UI用に26257/tcp8080を許可します:sudo ufw allow 8080 / tcp
- オプション:各サーバーで、NTPをインストールして構成します。 (簡単なテストの場合、これは確固たる要件ではありません)
すべてのサーバーのパブリックIPアドレスとプライベートIPアドレスをメモします。 このガイドでは、3台のサーバーのそれぞれに cockroach-01 、cockroach_01_public_ip、cockroach_01_public_ipなどの代用ホスト名とIPアドレスを使用します。 プライベートIPを見つけるには、DigitalOceanコントロールパネルからサーバーをクリックします。 プライベートIPは情報の一番上の行にリストされています。
ステップ1—CockroachDBをインストールする
クラスタ内の各ノードには、cockroachバイナリ(つまり、プログラム)のコピーが必要です。 最初のサーバーcockroach-01にCockroachDBをインストールしてから、他のサーバーにも同じようにインストールします。
開始するには、SSHを使用してcockroach-01にログインします。
- ssh sammy@cockroach_01_public_ip
次に、sudoユーザーのホームディレクトリから、最新のcockroachバイナリをダウンロードしてインストールします。
- wget https://binaries.cockroachdb.com/cockroach-latest.linux-amd64.tgz?s=do
バイナリを抽出します。
- tar -xf cockroach-latest.linux-amd64.tgz?s=do --strip=1 cockroach-latest.linux-amd64/cockroach
コマンドラインから簡単にアクセスできるように、バイナリを移動します。
- sudo mv cockroach /usr/local/bin
バージョンをチェックして、バイナリにアクセスできることを確認します。
- cockroach version
システムがcockroachコマンドを見つけられない場合は、このセクションをもう一度確認して、プログラムをダウンロードして解凍したことを確認してください。
最後に、ノードとして使用する予定の他の2つのサーバーに対してこれらのコマンドを繰り返します。 この例では、cockroach-02とcockroach-03です。
CockroachDBがすべてのマシンで使用できるようになったので、クラスターをセットアップできます。
ステップ2—最初のノードを開始する
最初のCockroachDBノードがクラスターを開始します。 この最初のノードについて特別なことは何もありません。 それはあなたが1つから始めて、それから他の人をそれに参加させなければならないということだけです。 このセクションでは、cockroach-01を使用します。
cockroach-01のプライベートIPアドレスをメモします。 DigitalOceanコントロールパネルから、このホストをクリックします。 プライベートIPは情報の一番上の行にリストされています。
クラスタを起動するための次のコマンドは、cockroach-01で実行する必要があります。 このコマンドは、SSL暗号化なしでノードを起動し(--insecure)、コマンドプロンプトの制御を返し(--background)、内部IPアドレス(--advertise-host)。 以下で強調表示されている変数cockroach_01_private_ipを実際のプライベートIPアドレスに置き換えます。
- cockroach start --insecure --background --advertise-host=cockroach_01_private_ip
注:ノードを起動すると、いくつかのフラグを使用して、データが保存されているディレクトリの変更など、その動作を変更できます。 これらのフラグは、ゴキブリスタートに記載されています。
ノード(およびクラスター)が稼働しているので、管理UIダッシュボード(クラスターに関する情報を表示するためにCockroachDBにバンドルされているツール)に移動して、ノードの詳細を表示できます。 http://cockroach_01_public_ip:8080に移動します。 今回はパブリックIPアドレスです。
ここでは、1つのノードが実行されていることがわかります。
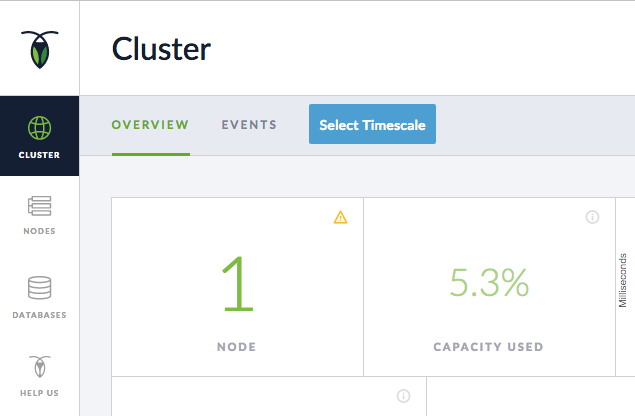
NODE タイルに警告の感嘆符(!)が表示されます。 警告の上にマウスを置くと、クラスターのレプリケーションが低レプリケーションであることが示されます。これは、ノードが不足していることを意味します。 現在ノードが1つしかないため、これは理解できます。 1つのノードでは、他のソースに十分に複製されていないため、データは障害に強いものではありません。 ノードがダウンすると、データは失われます。
次のステップで、他の2台のサーバーをノードとしてこのクラスターに追加することで修正します。 CockroachDBは、ノードを3つ持つことで、データのコピーが少なくとも3つあることを保証します。そのため、データを取り返しのつかないほど失うことなく、ノードを失う可能性があります。
ステップ3–クラスターにノード2と3を追加する
cockroach-02 サーバーで、手順2で行ったように、cockroach startコマンドを使用してCockroachDBノードを起動します。 ここでは、コマンドを更新して、プライベートIPアドレスを介して最初のサーバーのクラスターに参加するように指定します。 以下の強調表示された変数cockroach_02_private_ipとcockroach_01_private_ipを置き換えるには、cockroach-02とcockroach-01の両方のプライベートIPアドレスが必要になります。
- cockroach start --insecure --background \
- --advertise-host=cockroach_02_private_ip \
- --join=cockroach_01_private_ip:26257
プライベートIPアドレスを使用して、3番目のマシンcockroach-03でこのコマンドを繰り返します。 最初のノードにも参加させます。
- cockroach start --insecure --background \
- --advertise-host=cockroach_03_private_ip \
- --join=cockroach_01_private_ip:26257
これで、任意のノードから管理UIにアクセスすると、クラスターに3つのノードがあることがわかります。
http://cockroach_03_public_ip:8080
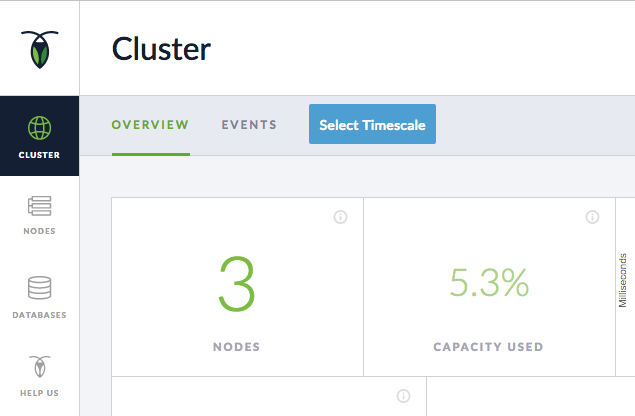
すべてのノードがクラスターを介して接続されたので、すべてのノードが同じデータにアクセスできるようになります。
(オプション)ステップ4 –データ分散のデモンストレーション
1つのノードにデータを書き込むときはいつでも、クラスター内の他のすべてのノードがそのノードにアクセスできます。 これを示す最も簡単な方法は、CockroachDBのサンプルデータを使用し、組み込みSQLクライアントからそれを表示することです。
最初のノードcockroach-01から、サンプルデータを生成します。
- cockroach gen example-data | cockroach sql
これにより、startrekというサンプルデータベースが作成されます。
これで、SQLクライアントを起動して、クラスター内にあるデータベースを表示できます。
- cockroach sql
- SHOW DATABASES;
startrekデータベースが一覧表示されます。このデータベースには、サンプルデータが含まれています。
+--------------------+
| Database |
+--------------------+
| information_schema |
| pg_catalog |
| startrek |
| system |
+--------------------+
次に、2番目のノードのターミナル cockroach-02 に移動し、同じコマンドを実行します。
- cockroach sql
- SHOW DATABASES;
別のノードでサンプルデータを生成した場合でも、データは分散されており、startrekデータベースには他のすべてのサーバーからアクセスできることがわかります。
また、任意のノードの管理UIのDATABASESサイドバーからデータベースが存在することを確認できます。 たとえば、http://cockroach_01_public_ip:8080/#/databases/で。
(オプション)ステップ5 –クラスターからのノードの削除
CockroachDBは、クラスター内のすべてのノードにデータを分散するだけでなく、サーバーが停止した場合のデータの可用性と整合性も保証します。
CockroachDBのノード障害に対する許容度の式は、(n-1)/ 2 です。ここで、nはクラスター内のノードの数です。 したがって、この3つのノードの例では、データを失うことなく1つのノードを失うことを許容できます。
これを示すために、クラスターからノードを削除し、クラスターのすべてのデータが引き続き利用可能であることを示します。 次に、ノードをクラスターに再参加させ、オフライン中に発生したすべての更新をノードが受信することを確認します。
2番目のノードcockroach-02から、まだSQLクライアントがない場合は、SQLクライアントを起動します。
- cockroach sql
サンプルデータベースのquotesテーブルの行数を数えます。
- SELECT COUNT(*) FROM startrek.quotes;
テーブルに200行あることがわかります。 CTRL+Cを押してSQLクライアントを終了します。
ここで、このノードをクラスターから削除し、すべてのデータが他のノードから引き続き利用できることを確認します。
使用していたのと同じノード( cockroach-02 )から、ゴキブリプロセスを停止します。
- cockroach quit
次に、他のノードの1つのターミナル( cockroach-03 など)に切り替えて、SQLクライアントを起動します。
- cockroach sql
前と同じコマンドを実行して、quotesテーブルの行数をカウントします。
- SELECT COUNT(*) FROM startrek.quotes;
クラスタ内のノードの1つが失われたにもかかわらず、200行のデータが残っていることがわかります。 これは、CockroachDBがシステム障害を正常に許容し、データの整合性を維持したことを意味します。
(オプション)ステップ6 —ノードをクラスターに再参加させる
また、CockroachDBがオンラインに戻ってきたサーバーを適切に処理することを示すこともできます。 まず、いくつかのデータを削除してから、削除したノードをクラスターに再参加させます。 再結合すると、CockroachDBが復活したノードから同じデータを自動的に削除することがわかります。
現在実行中のノードの1つ、たとえば cockroach-03 から、episodeが50より大きい引用符をすべて削除します。
- DELETE FROM startrek.quotes WHERE episode > 50;
- SELECT COUNT(*) FROM startrek.quotes;
133行のデータがあることがわかります。
ここで、クラスターから削除したノードのターミナル( cockroach-02 )に戻り、クラスターに再参加させます。
- cockroach start --insecure --background \
- --advertise-host=cockroach_02_private_ip \
- --join=cockroach_01_private_ip:26257
組み込みのSQLクライアントを起動します。
- cockroach sql
ここで、quotesテーブルに含まれる行数を数えます。
- SELECT COUNT(*) FROM startrek.quotes;
まだ133である必要があります。
そのため、更新が行われたときにオフラインであったにもかかわらず、ノードがクラスターに再参加するとすぐにノードが更新されます。
必要に応じて、サンプルデータを削除できます(cockroach sql CLIを引き続き使用)。
- DROP TABLE quotes;
- DROP TABLE episodes;
- DROP DATABASE startrek;
(オプション)ステップ7 –アプリケーションの接続
クラスターが稼働していると、それをアプリケーションのデータベースとして使用できます。 これには2つの部分が必要です。
- アプリケーションで使用するドライバー(CockroachDBはPostgreSQLドライバーで動作します)
- 適切な接続文字列
このガイドは一般的な例を示しています。 独自のアプリケーションの詳細を提供する必要があります。
アプリケーションに互換性のあるPostgreSQLクライアントドライバーのリストから適切なドライバーを選択してインストールします。
注: CockroachDBはPostgreSQLワイヤープロトコルをサポートしていますが、その SQL構文は異なり、PostgreSQLのドロップイン置換ではありません。
次に、アプリケーションがデータベースに接続する必要がある任意の時点で、適切な接続文字列を使用します。
接続文字列はポート26257に接続する必要があり、任意のノードのIPアドレスを使用できます。 つまり、ファイアウォールはポート26257での接続も許可する必要があります(前提条件で設定したとおり)。
たとえば、ユーザーsammyをlocalhost上のデータベースbankに接続するPHP/PDO接続文字列は次のとおりです。
PDO('pgsql:host=localhost;port=26257;dbname=bank;sslmode=disable',
'sammy', null, array(
PDO::ATTR_ERRMODE => PDO::ERRMODE_EXCEPTION,
PDO::ATTR_EMULATE_PREPARES => true,
));
PostgreSQLクライアントドライバーの使用に関する詳細については、CockroachDBに多数のコードサンプルがあります。
結論
この時点で、3ノードのクラスターを作成し、CockroachDBの分散された存続可能な機能を確認し、クラスターをアプリケーションに接続する方法を確認しました。
CockroachDBは動きの速いプロジェクトであるため、ダッシュボードに新しいバージョンのCockroachDBが利用可能です。 更新ボタンを使用して、へのリンクを表示することがあります。更新されたバイナリ。これを書いている時点では、手動でダウンロードしてインストールする必要があります。
ノードを追加してデプロイメントを水平方向にスケーリングする場合は、上記の2番目と3番目のノードの手順に従って4番目のノードに配置します。 cockroachバイナリをインストールし、新しいノードを既存のクラスターに参加させるだけです。
チェックアウト後にCockroachDBを本番環境で実行する場合は、推奨される本番環境設定をお読みください。
そして最後に、CockroachDBのドキュメントへの一般的なリンクがあります。