Ubuntu14.04パート1でPrometheusをクエリする方法
Prometheusの共同作成者であるJuliusVolzの記事
序章
Prometheusは、オープンソースの監視システムおよび時系列データベースです。 Prometheusの最も重要な側面の1つは、付随するクエリ言語を伴う多次元データモデルです。 このクエリ言語を使用すると、ディメンションデータを細かく分析して、運用上の質問にアドホックに回答したり、ダッシュボードに傾向を表示したり、システムの障害に関するアラートを生成したりできます。
このチュートリアルでは、Prometheus1.3.1にクエリを実行する方法を学習します。 適切なサンプルデータを使用できるようにするために、さまざまな種類の合成メトリックをエクスポートする3つの同一のデモサービスインスタンスを設定します。 次に、これらのメトリックをスクレイプして保存するためにPrometheusサーバーをセットアップします。 次に、メトリックの例を使用して、Prometheusにクエリを実行する方法を学習します。まず、単純なクエリから始めて、より高度なクエリに進みます。
このチュートリアルの後、ディメンションに基づいて時系列を選択およびフィルタリングする方法、時系列を集計および変換する方法、および異なるメトリック間で算術演算を行う方法を学習します。 フォローアップチュートリアルUbuntu14.04 Part 2 でPrometheusをクエリする方法では、このチュートリアルの知識に基づいて、より高度なクエリのユースケースを取り上げます。
前提条件
このチュートリアルに従うには、次のものが必要です。
- Ubuntu 14.04の初期サーバーセットアップガイドに従ってセットアップされた1つのUbuntu14.04サーバー(sudo非rootユーザーを含む)。
ステップ1—Prometheusをインストールする
このステップでは、Prometheusサーバーをダウンロード、構成、および実行して、3つの(まだ実行されていない)デモサービスインスタンスをスクレイプします。
まず、Prometheusをダウンロードします。
- wget https://github.com/prometheus/prometheus/releases/download/v1.3.1/prometheus-1.3.1.linux-amd64.tar.gz
tarballを抽出します。
- tar xvfz prometheus-1.3.1.linux-amd64.tar.gz
~/prometheus.ymlのホストファイルシステムに最小限のPrometheus構成ファイルを作成します。
- nano ~/prometheus.yml
次の内容をファイルに追加します。
# Scrape the three demo service instances every 5 seconds.
global:
scrape_interval: 5s
scrape_configs:
- job_name: 'demo'
static_configs:
- targets:
- 'localhost:8080'
- 'localhost:8081'
- 'localhost:8082'
nanoを保存して終了します。
この設定例では、Prometheusがデモインスタンスをスクレイプします。 Prometheusはプルモデルで動作するため、メトリックをプルするエンドポイントを認識するように構成する必要があります。 デモインスタンスはまだ実行されていませんが、後でポート8080、8081、および8082で実行されます。
nohupを使用し、バックグラウンドプロセスとしてPrometheusを起動します。
- nohup ./prometheus-1.3.1.linux-amd64/prometheus -storage.local.memory-chunks=10000 &
コマンドの先頭にあるnohupは、出力をstdoutではなくファイル~/nohup.outに送信します。 コマンドの最後にある&を使用すると、プロセスをバックグラウンドで実行し続けながら、追加のコマンドのプロンプトを返すことができます。 プロセスをフォアグラウンドに戻す(つまり、ターミナルの実行中のプロセスに戻す)には、同じターミナルでコマンドfgを使用します。
すべてがうまくいけば、~/nohup.outファイルに次のような出力が表示されます。
time="2016-11-23T03:10:33Z" level=info msg="Starting prometheus (version=1.3.1, branch=master, revision=be476954e80349cb7ec3ba6a3247cd712189dfcb)" source="main.go:75"
time="2016-11-23T03:10:33Z" level=info msg="Build context (go=go1.7.3, user=root@37f0aa346b26, date=20161104-20:24:03)" source="main.go:76"
time="2016-11-23T03:10:33Z" level=info msg="Loading configuration file prometheus.yml" source="main.go:247"
time="2016-11-23T03:10:33Z" level=info msg="Loading series map and head chunks..." source="storage.go:354"
time="2016-11-23T03:10:33Z" level=info msg="0 series loaded." source="storage.go:359"
time="2016-11-23T03:10:33Z" level=warning msg="No AlertManagers configured, not dispatching any alerts" source="notifier.go:176"
time="2016-11-23T03:10:33Z" level=info msg="Starting target manager..." source="targetmanager.go:76"
time="2016-11-23T03:10:33Z" level=info msg="Listening on :9090" source="web.go:240"
別の端末では、コマンドtail -f ~/nohup.outを使用してこのファイルの内容を監視できます。 ファイルにコンテンツが書き込まれると、端末に表示されます。
デフォルトでは、Prometheusはprometheus.yml(作成したばかり)から構成をロードし、メトリックデータを現在の作業ディレクトリの./dataに保存します。
-storage.local.memory-chunksフラグは、このチュートリアルでPrometheusのメモリ使用量をホストシステムの非常に少量のRAM(512MBのみ)と少数の保存された時系列に調整します。
これで、http://your_server_ip:9090/でPrometheusサーバーにアクセスできるようになります。 http://your_server_ip:9090/statusに移動し、 Targetsセクションでdemoジョブの3つのターゲットエンドポイントを見つけて、3つのデモインスタンスからメトリックを収集するように構成されていることを確認します。 3つのターゲットすべてのState列には、デモインスタンスがまだ開始されておらず、スクレイプできないため、ターゲットの状態がDOWNと表示されます。

ステップ2—デモインスタンスをインストールする
このセクションでは、3つのデモサービスインスタンスをインストールして実行します。
デモサービスをダウンロードします。
- wget https://github.com/juliusv/prometheus_demo_service/releases/download/0.0.4/prometheus_demo_service-0.0.4.linux-amd64.tar.gz
それを抽出します:
- tar xvfz prometheus_demo_service-0.0.4.linux-amd64.tar.gz
デモサービスを別々のポートで3回実行します。
- ./prometheus_demo_service -listen-address=:8080 &
- ./prometheus_demo_service -listen-address=:8081 &
- ./prometheus_demo_service -listen-address=:8082 &
&は、バックグラウンドでデモサービスを開始します。 何もログに記録されませんが、それぞれのポートの/metricsHTTPエンドポイントでPrometheusメトリックが公開されます。
これらのデモサービスは、いくつかのシミュレートされたサブシステムに関する合成メトリックをエクスポートします。 これらは:
- リクエスト数とレイテンシーを公開するHTTPAPIサーバー(パス、メソッド、およびレスポンスステータスコードでキー設定)
- 最後に成功した実行のタイムスタンプと処理されたバイト数を公開する定期的なバッチジョブ
- CPUの数とその使用量に関する総合的な指標
- ディスクの合計サイズとその使用量に関する総合的な指標
個々のメトリックは、後のセクションのクエリ例で紹介されています。
これで、Prometheusサーバーは3つのデモインスタンスのスクレイピングを自動的に開始するはずです。 http://your_server_ip:9090/statusにあるPrometheusサーバーのステータスページに移動し、demoジョブのターゲットがUP状態を示していることを確認します。

ステップ3—クエリブラウザを使用する
このステップでは、Prometheusに組み込まれているクエリとグラフのWebインターフェイスについて理解します。 このインターフェースは、アドホックなデータ探索やPrometheusのクエリ言語の学習には最適ですが、永続的なダッシュボードの構築には適しておらず、高度な視覚化機能をサポートしていません。 ダッシュボードの作成については、例PrometheusダッシュボードをGrafanaに追加する方法を参照してください。
Prometheusサーバーのhttp://your_server_ip:9090/graphに移動します。 次のようになります。

ご覧のとおり、グラフとコンソールの2つのタブがあります。 Prometheusでは、2つの異なるモードでデータをクエリできます。
- コンソールタブでは、現時点でクエリ式を評価できます。 クエリの実行後、テーブルには各結果の時系列の現在の値が表示されます(出力シリーズごとに1つのテーブル行)。
- グラフタブでは、指定した時間範囲でクエリ式をグラフ化できます。
Prometheusは数百万の時系列に拡張できるため、非常に高価なクエリを作成できます(これは、SQLデータベースの大きなテーブルからすべての行を選択するのと同じように考えてください)。 サーバーがタイムアウトしたり過負荷になったりするクエリを回避するには、クエリをすぐにグラフ化するのではなく、最初にConsoleビューでクエリの調査と構築を開始することをお勧めします。 ある時点でコストがかかる可能性のあるクエリを評価すると、同じクエリを一定期間グラフ化するよりもはるかに少ないリソースで済みます。
クエリを十分に絞り込んだら(ロード用に選択するシリーズ、実行する必要のある計算、出力時系列の数に関して)、グラフタブに切り替えて、時間の経過とともに表現を評価しました。 クエリがグラフ化できるほど安価であるかどうかを知ることは正確な科学ではなく、データ、レイテンシ要件、およびPrometheusサーバーを実行しているマシンの能力に依存します。 時間が経つにつれて、これを感じるでしょう。
テスト用のPrometheusサーバーは多くのデータを取得しないため、このチュートリアルでは実際にコストのかかるクエリを作成することはできません。 クエリの例は、リスクなしでGraphビューとConsoleビューの両方で表示できます。
グラフの時間範囲を増減するには、–または+ボタンをクリックします。 グラフの終了時刻を移動するには、を押します << また >> ボタン。 stacked チェックボックスをアクティブにすると、グラフをスタックできます。 最後に、
ステップ4—単純な時系列クエリの実行
クエリを開始する前に、Prometheusのデータモデルと用語を簡単に確認しましょう。 Prometheusは、基本的にすべてのデータを時系列として保存します。 各時系列は、メトリック名と、Prometheusがラベルと呼ぶキーと値のペアのセットによって識別されます。 メトリック名は、測定されているシステムの全体的な側面を示します(たとえば、プロセスの起動以降に処理されたHTTP要求の数http_requests_total)。 ラベルは、HTTPメソッドなどのメトリックのサブディメンションを区別するのに役立ちます(例: method="POST")またはパス(例: path="/api/foo")。 最後に、一連のサンプルが一連の実際のデータを形成します。 各サンプルはタイムスタンプと値で構成されます。タイムスタンプの精度はミリ秒で、値は常に64ビット浮動小数点値です。
作成できる最も単純なクエリは、指定されたメトリック名を持つすべてのシリーズを返します。 たとえば、デモサービスは、ダミーサービスによって処理される合成APIHTTPリクエストの数を表すメトリックdemo_api_request_duration_seconds_countをエクスポートします。 メトリック名に文字列duration_secondsが含まれているのはなぜか疑問に思われるかもしれません。 これは、このカウンターがdemo_api_request_duration_secondsという名前のより大きなヒストグラムメトリックの一部であり、主にリクエスト期間の分布を追跡するだけでなく、追跡されたリクエストの総数(ここでは_countでサフィックスが付けられます)を有用なものとして公開するためです。副産物。
コンソールクエリタブが選択されていることを確認し、ページ上部のテキストフィールドに次のクエリを入力し、実行ボタンをクリックしてクエリを実行します。
demo_api_request_duration_seconds_count
Prometheusは3つのサービスインスタンスを監視しているため、追跡されたサービスインスタンス、パス、HTTPメソッド、およびHTTPステータスコードごとに1つずつ、このメトリック名を持つ27の結果の時系列を含む表形式の出力が表示されます。 サービスインスタンス自体によって設定されたラベル(method、path、およびstatus)に加えて、シリーズには適切なjobおよびinstanceがあります。異なるサービスインスタンスを互いに区別するラベル。 Prometheusは、スクレイプされたターゲットからの時系列を保存するときに、これらのラベルを自動的に添付します。 出力は次のようになります。

右側の表の列に表示されている数値は、各時系列の現在の値です。 このクエリと後続のクエリの出力をグラフ化して(グラフタブをクリックし、実行をもう一度クリックして)、時間の経過とともに値がどのように変化するかを確認してください。
ラベルマッチャーを追加して、ラベルに基づいて返されるシリーズを制限できるようになりました。 ラベルマッチャーは、中括弧で囲まれたメトリック名の直後に続きます。 最も単純な形式では、特定のラベルの正確な値を持つ系列をフィルタリングします。 たとえば、このクエリでは、GETリクエストのリクエスト数のみが表示されます。
demo_api_request_duration_seconds_count{method="GET"}
マッチャーはコンマを使用して組み合わせることができます。 たとえば、インスタンスlocalhost:8080とジョブdemoからのメトリックのみを追加でフィルタリングできます。
demo_api_request_duration_seconds_count{instance="localhost:8080",method="GET",job="demo"}
結果は次のようになります。

複数のマッチャーを組み合わせる場合、シリーズを選択するには、それらすべてを一致させる必要があります。 上記の式は、ポート8080で実行されているサービスインスタンスのAPIリクエストカウントのみを返します。HTTPメソッドはGETでした。 また、demoジョブに属するメトリックのみを選択するようにします。
注:時系列を選択するときは、常にjobラベルを指定することをお勧めします。 これにより、別のジョブから同じ名前のメトリックを誤って選択することがなくなります(もちろん、それが本当に目標でない限り)。 このチュートリアルでは1つのジョブのみを監視しますが、このプラクティスの重要性を強調するために、以下の例のほとんどではジョブ名で選択します。
Prometheusは、等式マッチングに加えて、非等式マッチング(!=)、正規表現マッチング(=~)、および負の正規表現マッチング(!~)をサポートしています。 メトリック名を完全に省略して、ラベルマッチャーのみを使用してクエリを実行することもできます。 たとえば、pathラベルが/apiで始まるすべてのシリーズ(メトリック名またはジョブに関係なく)を一覧表示するには、次のクエリを実行できます。
{path=~"/api.*"}
Prometheusでは正規表現は常に完全な文字列と一致するため、上記の正規表現は.*で終了する必要があります。
結果の時系列は、異なるメトリック名を持つシリーズの混合になります。

これで、メトリック名とラベル値の組み合わせによって時系列を選択する方法がわかりました。
ステップ5—レートおよびその他のデリバティブの計算
このセクションでは、時間の経過に伴うメトリックのレートまたはデルタを計算する方法を学習します。
Prometheusで使用する最も頻繁な関数の1つは、rate()です。 インストルメント化されたサービスで直接イベントレートを計算する代わりに、Prometheusでは、生のカウンターを使用してイベントを追跡し、クエリ時間中にPrometheusサーバーにアドホックでレートを計算させるのが一般的です(これには、レートスパイクを失わないなどの多くの利点がありますスクレイプ間、およびクエリ時に動的平均化ウィンドウを選択できるようになります)。 カウンタは、監視対象サービスが開始される0から開始され、サービスプロセスの存続期間にわたって継続的に増分されます。 時折、監視対象のプロセスが再起動すると、そのカウンターが0にリセットされ、そこから再び上昇し始めます。 生のカウンターをグラフ化することは、たまにリセットされるだけで増加し続ける線が表示されるため、通常はあまり役に立ちません。 デモサービスのAPIリクエスト数をグラフ化すると、次のことがわかります。
demo_api_request_duration_seconds_count{job="demo"}
次のようになります。

カウンターを便利にするために、rate()関数を使用して、毎秒の増加率を計算できます。 シリーズマッチャーの後に範囲セレクター([5m]など)を提供することにより、レートを平均化する時間枠をrate()に指示する必要があります。 たとえば、過去5分間の平均として、上記のカウンターメトリックの1秒あたりの増加を計算するには、次のクエリをグラフ化します。
rate(demo_api_request_duration_seconds_count{job="demo"}[5m])
結果は今でははるかに便利です:
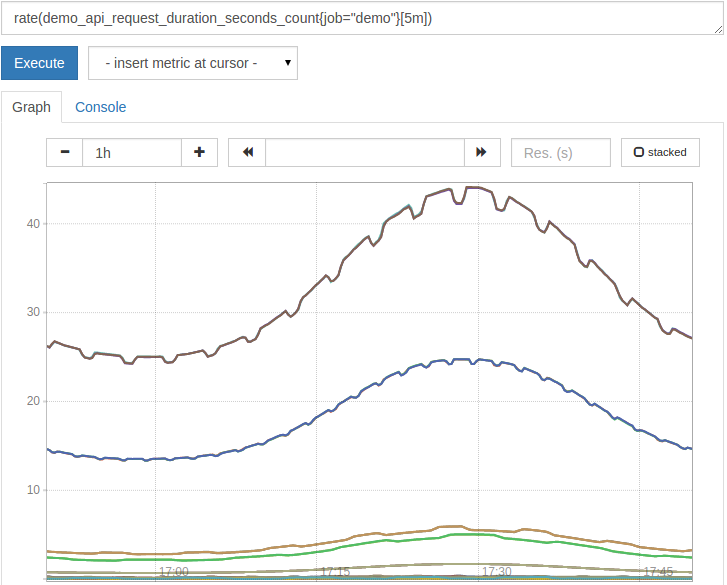
rate()はスマートであり、カウンター値の減少がリセットであると想定することにより、カウンターリセットを自動的に調整します。
rate()の変形はirate()です。 rate()は、指定された時間枠(この場合は5分)のすべてのサンプルのレートを平均しますが、irate()は、過去の2つのサンプルのみを振り返ります。 それでも、これら2つのサンプルの時間を最大限に振り返る距離を知るには、時間枠([5m]など)を指定する必要があります。 irate()はレートの変化に対してより速く反応するため、通常はグラフでの使用が推奨されます。 対照的に、rate()はよりスムーズなレートを提供し、アラート表現での使用をお勧めします(短いレートのスパイクは減衰され、夜間に目覚めないため)。
irate()を使用すると、上のグラフは次のようになり、リクエストレートの短い断続的な低下が明らかになります。

rate()およびirate()は、常に毎秒レートを計算します。 場合によっては、合計量を知りたい場合があります。これにより、ある時間枠でカウンターが増加しましたが、それでもカウンターのリセットは修正されています。 これは、increase()機能で実現できます。 たとえば、過去1時間に処理されたリクエストの総数を計算するには、次のクエリを実行します。
increase(demo_api_request_duration_seconds_count{job="demo"}[1h])
カウンター(増加のみ可能)の他に、ゲージメトリックがあります。 ゲージは、温度やディスクの空き容量など、時間の経過とともに上下する可能性のある値です。 時間の経過に伴うゲージの変化を計算する場合、rate() / irate() /increase()ファミリーの関数を使用することはできません。 これらはすべて、メトリック値の減少をカウンターリセットとして解釈し、それを補正するため、カウンターを対象としています。 代わりに、deriv()関数を使用できます。この関数は、線形回帰に基づいてゲージの2階導関数を計算します。
たとえば、過去15分間の線形回帰に基づいて、デモサービスによってエクスポートされた架空のディスク使用量がどれだけ速く増加または減少しているか(MiB /秒)を確認するには、次のクエリを実行できます。
deriv(demo_disk_usage_bytes{job="demo"}[15m])
結果は次のようになります。

ゲージのデルタとトレンドの計算の詳細については、 delta()および predict_linear()関数も参照してください。
これで、さまざまな平均化動作を使用して1秒あたりのレートを計算する方法、レート計算でカウンターリセットを処理する方法、およびゲージの導関数を計算する方法がわかりました。
ステップ6—時系列での集計
このセクションでは、個々のシリーズを集約する方法を学習します。
Prometheusは、高次元の詳細でデータを収集します。これにより、メトリック名ごとに多くのシリーズが作成される可能性があります。 ただし、多くの場合、すべてのディメンションを気にする必要はなく、シリーズが多すぎて、合理的な方法で一度にすべてをグラフ化できない場合もあります。 解決策は、いくつかのディメンションを集約し、関心のあるディメンションのみを保持することです。 たとえば、デモサービスは、method、path、およびstatusによってAPIHTTPリクエストを追跡します。 Prometheusは、ノードエクスポータからメトリクスをスクレイピングするときに、このメトリクスにさらにディメンションを追加します。メトリクスがどのプロセスから来たかを追跡するinstanceおよびjobラベルです。 ここで、すべてのディメンションの合計リクエストレートを確認するには、sum()集計演算子を使用できます。
sum(rate(demo_api_request_duration_seconds_count{job="demo"}[5m]))
ただし、これはすべてのディメンションを集約し、単一の出力系列を作成します。

ただし、通常は、出力のディメンションの一部を保持する必要があります。 このため、sum()およびその他のアグリゲーターは、集約するディメンションを指定するwithout(<label names>)句をサポートしています。 by(<label names>)句の反対側の代替句もあり、保持するラベル名を指定できます。 3つのサービスインスタンスすべてとすべてのパスで合計された合計リクエストレートを知りたいが、結果をメソッドとステータスコードで分割したい場合は、次のクエリを実行できます。
sum without(method, status) (rate(demo_api_request_duration_seconds_count{job="demo"}[5m]))
これは次と同等です。
sum by(instance, path, job) (rate(demo_api_request_duration_seconds_count{job="demo"}[5m]))
結果の合計は、instance、path、およびjobによってグループ化されます。

注:集計を適用するの前に、常にrate()、irate()、またはincrease()を計算してください。 最初に集計を適用すると、カウンターリセットが非表示になり、これらの関数が正しく機能しなくなります。
Prometheusは、次の集計演算子をサポートしています。これらの演算子はそれぞれ、by()またはwithout()句をサポートして、保持するディメンションを選択します。
sum:集約されたグループ内のすべての値を合計します。min:集約されたグループ内のすべての値の最小値を選択します。max:集約されたグループ内のすべての値の最大値を選択します。avg:集約されたグループ内のすべての値の平均(算術平均)を計算します。stddev:集約されたグループ内のすべての値の標準偏差を計算します。stdvar:集約されたグループ内のすべての値の標準分散を計算します。count:集約されたグループ内のシリーズの総数を計算します。
これで、シリーズのリストを集計する方法と、関心のあるディメンションのみを保持する方法を学習しました。
ステップ7—算術演算の実行
このセクションでは、Prometheusで算術演算を行う方法を学習します。
最も単純な算術の例として、Prometheusを数値計算機として使用できます。 たとえば、Consoleビューで次のクエリを実行します。
(4 + 7) * 3
33の単一のスカラー出力値を取得します。

スカラー値は、ラベルのない単純な数値です。 これをより便利にするために、Prometheusでは一般的な算術演算子(+、-、*、/、%)を適用できます。時系列ベクトル全体に。 たとえば、次のクエリは、シミュレートされた最後のバッチジョブ実行によって処理されたバイト数をMiBに変換します。
demo_batch_last_run_processed_bytes{job="demo"} / 1024 / 1024
結果はMiBに表示されます。

これらのタイプの単位変換には単純な演算を使用するのが一般的ですが、優れた視覚化ツール(Grafanaなど)も変換を処理します。
Prometheusの専門(そしてPrometheusが本当に輝いているところ!)は、2セットの時系列間のバイナリ演算です。 2項系列のセット間で二項演算子を使用する場合、Prometheusは、演算の左側と右側で同じラベルセットを持つ要素を自動的に照合し、演算子を各照合ペアに適用して出力系列を生成します。
たとえば、demo_api_request_duration_seconds_sumメトリックは、HTTPリクエストへの応答に費やされた秒数を示し、demo_api_request_duration_seconds_countは、多くのHTTPリクエストがあったことを示します。 両方の指標のディメンションは同じです(method、path、status、instance、job)。 これらの各ディメンションの平均リクエストレイテンシを計算するには、リクエストに費やされた合計時間をリクエストの総数で割った比率をクエリするだけです。
rate(demo_api_request_duration_seconds_sum{job="demo"}[5m])
/
rate(demo_api_request_duration_seconds_count{job="demo"}[5m])
また、rate()関数を操作の両側にラップして、過去5分間に発生したリクエストのレイテンシーのみを考慮することに注意してください。 これにより、カウンターリセットに対する回復力も追加されます。
結果の平均リクエストレイテンシグラフは次のようになります。

しかし、ラベルが両側で正確に一致しない場合はどうすればよいでしょうか。 これは、操作の両側に異なるサイズの時系列のセットがある場合に特に発生します。これは、一方の側がもう一方の側よりも多くのディメンションを持っているためです。 たとえば、デモジョブは、さまざまなモード(idle、user、system)で費やされた架空のCPU時間を、modeラベルの寸法。 また、架空のCPUの総数をdemo_num_cpusとしてエクスポートします(このメトリックに追加のディメンションはありません)。 1つを他のモードで割って、3つのモードのそれぞれの平均CPU使用率をパーセントで算出しようとすると、クエリは出力を生成しません。
# BAD!
# Multiply by 100 to get from a ratio to a percentage
rate(demo_cpu_usage_seconds_total{job="demo"}[5m]) * 100
/
demo_num_cpus{job="demo"}
これらの1対多または多対1のマッチングでは、マッチングに使用するラベルのサブセットをPrometheusに指示する必要があります。また、余分な次元を処理する方法を指定する必要もあります。 一致を解決するために、一致するラベルを指定する二項演算子にon(<label names>)句を追加します。 ファンアウトして、大きい方の追加ディメンションの個々の値で計算をグループ化するために、左側または右側の追加ディメンションをそれぞれリストするgroup_left(<label names>)またはgroup_right(<label names>)句を追加します。 。
この場合の正しいクエリは次のようになります。
# Multiply by 100 to get from a ratio to a percentage
rate(demo_cpu_usage_seconds_total{job="demo"}[5m]) * 100
/ on(job, instance) group_left(mode)
demo_num_cpus{job="demo"}
結果は次のようになります。

on(job, instance)は、jobおよびinstanceラベル(したがって、modeラベルではなく)の左右の系列のみを照合するようにオペレーターに指示します。右側には存在しません)、group_left(mode)句は、モードごとのCPU使用率の平均をファンアウトして表示するようにオペレーターに指示します。 これは、多対1のマッチングの場合です。 逆(1対多)マッチングを行うには、同じ方法でgroup_right(<label names>)句を使用します。
これで、時系列のセット間で算術を使用する方法と、さまざまなディメンションを処理する方法を理解できました。
結論
このチュートリアルでは、デモサービスインスタンスのグループを設定し、Prometheusでそれらを監視しました。 次に、収集したデータに対してさまざまなクエリ手法を適用して、関心のある質問に答える方法を学びました。 これで、系列を選択してフィルタリングする方法、ディメンションを集計する方法、レートやデリバティブを計算する方法、または算術演算を行う方法を理解できました。 また、一般的なクエリの構築にアプローチする方法と、Prometheusサーバーの過負荷を回避する方法も学びました。
ヒストグラムからパーセンタイルを計算する方法、タイムスタンプベースのメトリックを処理する方法、サービスインスタンスの状態をクエリする方法など、Prometheusのクエリ言語の詳細については、Ubuntu14.04でPrometheusをクエリする方法パート2をご覧ください。 。