Ubuntu14.04でキープアライブおよびフローティングIPを使用して高可用性HAProxyサーバーをセットアップする方法
序章
高可用性は、障害が発生した場合にアプリケーションが作業を自動的に再起動したり、別の対応可能なシステムに再ルーティングしたりできるようにするシステム設計の機能です。 サーバーに関しては、高可用性システムをセットアップするために必要ないくつかの異なるテクノロジーがあります。 作業をリダイレクトできるコンポーネントが必要であり、障害を監視し、中断が検出された場合にシステムを移行するメカニズムが必要です。
keepalivedデーモンを使用して、サービスまたはシステムを監視し、問題が発生した場合にスタンバイに自動的にフェイルオーバーすることができます。 このガイドでは、keepalivedを使用してロードバランサーの高可用性を設定する方法を示します。 2つの対応するロードバランサー間で移動できるフローティングIPアドレスを構成します。 これらはそれぞれ、2つのバックエンドWebサーバー間でトラフィックを分割するように構成されます。 プライマリロードバランサーがダウンすると、フローティングIPが自動的にセカンドロードバランサーに移動し、サービスを再開できるようになります。

ノート: DigitalOceanロードバランサー are a fully-managed, highly available load balancing service. The Load Balancer service can fill the same role as the manual high availability setup described here. Follow our ロードバランサーの設定に関するガイド if you wish to evaluate that option.
前提条件
このガイドを完了するには、DigitalOceanアカウントに4つのUbuntu14.04サーバーを作成する必要があります。 すべてのサーバーは同じデータセンター内に配置する必要があり、プライベートネットワークを有効にする必要があります。
これらの各サーバーでは、sudoアクセスで構成されたroot以外のユーザーが必要になります。 Ubuntu 14.04初期サーバーセットアップガイドに従って、これらのユーザーのセットアップ方法を学ぶことができます。
サーバーネットワーク情報の検索
インフラストラクチャコンポーネントの実際の構成を開始する前に、各サーバーに関する情報を収集することをお勧めします。
このガイドを完了するには、サーバーに関する次の情報が必要です。
- ウェブサーバー:プライベートIPアドレス
- ロードバランサープライベートおよびアンカーIPアドレス
プライベートIPアドレスの検索
DropletのプライベートIPアドレスを見つける最も簡単な方法は、curlを使用して、DigitalOceanメタデータサービスからプライベートIPアドレスを取得することです。 このコマンドは、ドロップレット内から実行する必要があります。 各ドロップレットに次のように入力します。
- curl 169.254.169.254/metadata/v1/interfaces/private/0/ipv4/address && echo
正しいIPアドレスがターミナルウィンドウに出力されます。
Output10.132.20.236
アンカーIPアドレスの検索
「アンカーIP」は、フローティングIPがDigitalOceanサーバーに接続されたときにバインドするローカルプライベートIPアドレスです。 これは、ハイパーバイザーレベルで実装された、通常のeth0アドレスの単なるエイリアスです。
この値を取得する最も簡単でエラーが発生しにくい方法は、DigitalOceanメタデータサービスから直接取得することです。 curlを使用すると、次のように入力して、各サーバー上のこのエンドポイントにアクセスできます。
- curl 169.254.169.254/metadata/v1/interfaces/public/0/anchor_ipv4/address && echo
アンカーIPは独自の行に印刷されます。
Output10.17.1.18
Webサーバーのインストールと構成
上記のデータを収集したら、サービスの構成に進むことができます。
ノート
このセットアップでは、Webサーバーレイヤー用に選択されたソフトウェアはかなり互換性があります。 このガイドでは、一般的で構成がかなり簡単なNginxを使用します。 Apacheまたは(本番環境に対応した)言語固有のWebサーバーに慣れている場合は、代わりにそれを自由に使用してください。 HAProxyは、直接クライアント接続を処理するのと同じように要求を処理できるバックエンドWebサーバーにクライアント要求を渡すだけです。
まず、バックエンドWebサーバーをセットアップします。 これらのサーバーは両方ともまったく同じコンテンツを提供します。 プライベートIPアドレスを介したWeb接続のみを受け入れます。 これにより、後で構成する2つのHAProxyサーバーのいずれかを介してトラフィックが転送されるようになります。
ロードバランサーの背後にWebサーバーを設定すると、要求の負担をいくつかの同一のWebサーバーに分散できます。 トラフィックのニーズが変化した場合、この層にWebサーバーを追加または削除することで、新しい需要に合わせて簡単に拡張できます。
Nginxのインストール
この機能を提供するために、WebサービングマシンにNginxをインストールします。
sudoユーザーを使用して、Webサーバーとして使用する2台のマシンにログインすることから始めます。 各Webサーバーのローカルパッケージインデックスを更新し、次のように入力してNginxをインストールします。
- sudo apt-get update
- sudo apt-get install nginx
ロードバランサーからのリクエストのみを許可するようにNginxを構成する
次に、Nginxインスタンスを構成します。 サーバーのプライベートIPアドレスでのみリクエストをリッスンするようにNginxに指示します。 さらに、2つのロードバランサーのプライベートIPアドレスからのリクエストのみを処理します。
これらの変更を行うには、各WebサーバーでデフォルトのNginxサーバーブロックファイルを開きます。
- sudo nano /etc/nginx/sites-available/default
まず、listenディレクティブを変更します。 listenディレクティブを変更して、ポート80で現在のWebサーバーのプライベートIPアドレスをリッスンします。 余分なlisten行を削除します。 次のようになります。
server {
listen web_server_private_IP:80;
. . .
その後、2つのallowディレクティブを設定して、2つのロードバランサーのプライベートIPアドレスから発信されるトラフィックを許可します。 これをdeny allルールでフォローアップして、他のすべてのトラフィックを禁止します。
server {
listen web_server_private_IP:80;
allow load_balancer_1_private_IP;
allow load_balancer_2_private_IP;
deny all;
. . .
終了したら、ファイルを保存して閉じます。
次のように入力して、行った変更が有効なNginx構文を表していることをテストします。
- sudo nginx -t
問題が報告されていない場合は、次のように入力してNginxデーモンを再起動します。
- sudo service nginx restart
変更のテスト
Webサーバーが正しく制限されていることをテストするために、さまざまな場所からcurlを使用してリクエストを行うことができます。
Webサーバー自体で、次のように入力して、ローカルコンテンツの簡単なリクエストを試すことができます。
- curl 127.0.0.1
Nginxサーバーブロックファイルに設定した制限のため、このリクエストは実際には拒否されます。
Outputcurl: (7) Failed to connect to 127.0.0.1 port 80: Connection refused
これは予想されたものであり、実装しようとした動作を反映しています。
これで、ロードバランサーのいずれかから、WebサーバーのパブリックIPアドレスのいずれかをリクエストできます。
- curl web_server_public_IP
繰り返しますが、これは失敗するはずです。 Webサーバーはパブリックインターフェイスをリッスンしていません。さらに、パブリックIPアドレスを使用する場合、Webサーバーはロードバランサーからの要求で許可されたプライベートIPアドレスを認識しません。
Outputcurl: (7) Failed to connect to web_server_public_IP port 80: Connection refused
ただし、WebサーバーのプライベートIPアドレスを使用して要求を行うように呼び出しを変更すると、正しく機能するはずです。
- curl web_server_private_IP
デフォルトのNginxindex.htmlページが返されます。
Output<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
. . .
両方のロードバランサーから両方のWebサーバーにこれをテストします。 プライベートIPアドレスに対する各要求は成功する必要がありますが、パブリックアドレスに対して行われる各要求は失敗する必要があります。
上記の動作が実証されたら、次に進むことができます。 これで、バックエンドWebサーバーの構成が完了しました。
HAProxyをインストールして設定する
次に、HAProxyロードバランサーを設定します。 これらはそれぞれWebサーバーの前に配置され、2つのバックエンドサーバー間でリクエストを分割します。 これらのロードバランサーは完全に冗長です。 常に1つだけがトラフィックを受信します。
HAProxy構成は、両方のWebサーバーに要求を渡します。 ロードバランサーは、アンカーIPアドレスでリクエストをリッスンします。 前述のように、これは、ドロップレットに接続されたときにフローティングIPアドレスがバインドするIPアドレスです。 これにより、フローティングIPアドレスから発信されたトラフィックのみが転送されます。
HAProxyをインストールする
ロードバランサーで実行する必要がある最初のステップは、haproxyパッケージをインストールすることです。 これはデフォルトのUbuntuリポジトリにあります。 ロードバランサーのローカルパッケージインデックスを更新し、次のように入力してHAProxyをインストールします。
- sudo apt-get update
- sudo apt-get install haproxy
HAProxyを構成する
HAProxyを処理するときに変更する必要がある最初の項目は、/etc/default/haproxyファイルです。 そのファイルをエディターで今すぐ開きます。
- sudo nano /etc/default/haproxy
このファイルは、HAProxyが起動時に起動するかどうかを決定します。 サーバーの電源を入れるたびにサービスを自動的に開始する必要があるため、ENABLEDの値を「1」に変更する必要があります。
# Set ENABLED to 1 if you want the init script to start haproxy.
ENABLED=1
# Add extra flags here.
#EXTRAOPTS="-de -m 16"
上記の編集を行った後、ファイルを保存して閉じます。
次に、メインのHAProxy構成ファイルを開くことができます。
- sudo nano /etc/haproxy/haproxy.cfg
調整する必要がある最初の項目は、HAProxyが動作するモードです。 TCP、つまりレイヤー4の負荷分散を構成します。 これを行うには、defaultセクションのmode行を変更する必要があります。 ログを処理する直後のオプションも変更する必要があります。
. . .
defaults
log global
mode tcp
option tcplog
. . .
ファイルの最後で、フロントエンド構成を定義する必要があります。 これにより、HAProxyが着信接続をリッスンする方法が決まります。 HAProxyをロードバランサーのアンカーIPアドレスにバインドします。 これにより、フローティングIPアドレスから発信されたトラフィックをリッスンできるようになります。 わかりやすくするために、フロントエンドを「www」と呼びます。 また、トラフィックを渡すデフォルトのバックエンドを指定します(これはすぐに構成します)。
. . .
defaults
log global
mode tcp
option tcplog
. . .
frontend www
bind load_balancer_anchor_IP:80
default_backend nginx_pool
次に、バックエンドセクションを構成できます。 これにより、HAProxyが受信するトラフィックを渡すダウンストリームの場所が指定されます。 この場合、これは、構成した両方のNginxWebサーバーのプライベートIPアドレスになります。 従来のラウンドロビンバランシングを指定し、モードを再び「tcp」に設定します。
. . .
defaults
log global
mode tcp
option tcplog
. . .
frontend www
bind load_balancer_anchor_IP:80
default_backend nginx_pool
backend nginx_pool
balance roundrobin
mode tcp
server web1 web_server_1_private_IP:80 check
server web2 web_server_2_private_IP:80 check
上記の変更が完了したら、ファイルを保存して閉じます。
次のように入力して、行った構成の変更が有効なHAProxy構文を表していることを確認します。
- sudo haproxy -f /etc/haproxy/haproxy.cfg -c
エラーが報告されなかった場合は、次のように入力してサービスを再起動します。
- sudo service haproxy restart
変更のテスト
curlで再度テストすることにより、構成が有効であることを確認できます。
ロードバランサーサーバーから、ローカルホスト、ロードバランサー自体のパブリックIPアドレス、またはサーバー自体のプライベートIPアドレスを要求してみてください。
- curl 127.0.0.1
- curl load_balancer_public_IP
- curl load_balancer_private_IP
これらはすべて、次のようなメッセージで失敗するはずです。
Outputcurl: (7) Failed to connect to address port 80: Connection refused
ただし、ロードバランサーのアンカーIPアドレスにリクエストを送信すると、正常に完了するはずです。
- curl load_balancer_anchor_IP
2つのバックエンドWebサーバーのいずれかからルーティングされたデフォルトのNginxindex.htmlページが表示されます。
Output<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
. . .
この動作がシステムの動作と一致する場合は、ロードバランサーが正しく構成されています。
キープアライブのビルドとインストール
現在、実際のサービスが稼働しています。 ただし、アクティブなロードバランサーで問題が発生した場合にトラフィックをリダイレクトする方法がないため、インフラストラクチャはまだ高可用性ではありません。 これを修正するために、ロードバランサーサーバーにkeepalivedデーモンをインストールします。 これは、アクティブなロードバランサーが使用できなくなった場合にフェイルオーバー機能を提供するコンポーネントです。
Ubuntuのデフォルトリポジトリにはkeepalivedのバージョンがありますが、それは古く、構成が機能しなくなるいくつかのバグがあります。 代わりに、最新バージョンのkeepalivedをソースからインストールします。
始める前に、ソフトウェアをビルドするために必要な依存関係を把握する必要があります。 build-essentialメタパッケージは、必要なコンパイルツールを提供しますが、libssl-devパッケージには、keepalivedが構築する必要のあるSSL開発ライブラリが含まれています。
- sudo apt-get install build-essential libssl-dev
依存関係が設定されたら、keepalivedのtarballをダウンロードできます。 このページにアクセスして、ソフトウェアの最新バージョンを見つけてください。 最新バージョンを右クリックして、リンクアドレスをコピーします。 サーバーに戻り、ホームディレクトリに移動し、wgetを使用してコピーしたリンクを取得します。
- cd ~
- wget http://www.keepalived.org/software/keepalived-1.2.19.tar.gz
tarコマンドを使用して、アーカイブを展開します。 結果のディレクトリに移動します。
- tar xzvf keepalived*
- cd keepalived*
次のように入力して、デーモンをビルドしてインストールします。
- ./configure
- make
- sudo make install
これで、デーモンが両方のロードバランサーシステムにインストールされます。
キープアライブアップスタートスクリプトを作成する
keepalivedをインストールすると、すべてのバイナリとサポートファイルがシステム上の所定の場所に移動しました。 ただし、含まれていなかったのは、Ubuntu14.04システムのUpstartスクリプトでした。
keepalivedサービスを処理できる非常にシンプルなUpstartスクリプトを作成できます。 /etc/initディレクトリ内のkeepalived.confというファイルを開いて開始します。
- sudo nano /etc/init/keepalived.conf
内部では、keepalivedが提供する機能の簡単な説明から始めることができます。 付属のmanページの説明を使用します。 次に、サービスを開始および停止するランレベルを指定します。 このサービスをすべての通常の状態(ランレベル2〜5)でアクティブにし、他のすべてのランレベル(たとえば、再起動、電源オフ、またはシングルユーザーモードが開始されたとき)で停止する必要があります。
description "load-balancing and high-availability service"
start on runlevel [2345]
stop on runlevel [!2345]
このサービスは、Webサービスを引き続き利用できるようにするために不可欠であるため、障害が発生した場合にこのサービスを再開します。 次に、サービスを開始する実際のexec行を指定できます。 Upstartがpidを正しく追跡できるように、--dont-forkオプションを追加する必要があります。
description "load-balancing and high-availability service"
start on runlevel [2345]
stop on runlevel [!2345]
respawn
exec /usr/local/sbin/keepalived --dont-fork
終了したら、ファイルを保存して閉じます。
キープアライブ構成ファイルを作成する
Upstartファイルを配置したら、keepalivedの構成に進むことができます。
サービスは、/etc/keepalivedディレクトリで構成ファイルを探します。 両方のロードバランサーに今すぐそのディレクトリを作成します。
- sudo mkdir -p /etc/keepalived
プライマリロードバランサーの構成の作成
次に、プライマリサーバーとして使用するロードバランサーサーバーで、メインのkeepalived構成ファイルを作成します。 デーモンは、/etc/keepalivedディレクトリ内でkeepalived.confというファイルを探します。
- sudo nano /etc/keepalived/keepalived.conf
内部では、vrrp_scriptブロックを開いて、HAProxyサービスのヘルスチェックを定義することから始めます。 これにより、keepalivedはロードバランサーの障害を監視できるようになり、プロセスがダウンしていることを通知して、対策の回復を開始できます。
チェックはとても簡単です。 2秒ごとに、haproxyというプロセスがまだpidを要求していることを確認します。
vrrp_script chk_haproxy {
script "pidof haproxy"
interval 2
}
次に、vrrp_instanceというブロックを開きます。 これは、keepalivedが高可用性を実装する方法を定義する主要な構成セクションです。
まず、keepalivedに、プライベートインターフェイスであるeth1を介してピアと通信するように指示します。 プライマリサーバーを構成しているので、state構成を「MASTER」に設定します。 これは、デーモンがピアに接続して選択を行うことができるまで、keepalivedが使用する初期値です。
選挙中、priorityオプションを使用して、どのメンバーが選出されるかを決定します。 決定は、この設定で最も多いサーバーの数に基づいて行われます。 プライマリサーバーには「200」を使用します。
vrrp_script chk_nginx {
script "pidof nginx"
interval 2
}
vrrp_instance VI_1 {
interface eth1
state MASTER
priority 200
}
次に、両方のノードで共有されるこのクラスターグループにIDを割り当てます。 この例では「33」を使用します。 unicast_src_ipをprimaryロードバランサーのプライベートIPアドレスに設定する必要があります。 unicast_peerをセカンダリロードバランサーのプライベートIPアドレスに設定します。
vrrp_script chk_haproxy {
script "pidof haproxy"
interval 2
}
vrrp_instance VI_1 {
interface eth1
state MASTER
priority 200
virtual_router_id 33
unicast_src_ip primary_private_IP
unicast_peer {
secondary_private_IP
}
}
次に、keepalivedデーモンが相互に通信するための簡単な認証を設定できます。 これは、連絡先のピアが正当であることを確認するための基本的な手段にすぎません。 authenticationサブブロックを作成します。 内部で、auth_typeを設定してパスワード認証を指定します。 auth_passパラメーターには、両方のノードで使用される共有シークレットを設定します。 残念ながら、最初の8文字だけが重要です。
vrrp_script chk_haproxy {
script "pidof haproxy"
interval 2
}
vrrp_instance VI_1 {
interface eth1
state MASTER
priority 200
virtual_router_id 33
unicast_src_ip primary_private_IP
unicast_peer {
secondary_private_IP
}
authentication {
auth_type PASS
auth_pass password
}
}
次に、keepalivedに、ファイルの先頭に作成したchk_haproxyというラベルの付いたチェックを使用して、ローカルシステムの状態を判断するように指示します。 最後に、notify_masterスクリプトを設定します。このスクリプトは、このノードがペアの「マスター」になるたびに実行されます。 このスクリプトは、フローティングIPアドレスの再割り当てをトリガーする役割を果たします。 このスクリプトをすぐに作成します。
vrrp_script chk_haproxy {
script "pidof haproxy"
interval 2
}
vrrp_instance VI_1 {
interface eth1
state MASTER
priority 200
virtual_router_id 33
unicast_src_ip primary_private_IP
unicast_peer {
secondary_private_IP
}
authentication {
auth_type PASS
auth_pass password
}
track_script {
chk_haproxy
}
notify_master /etc/keepalived/master.sh
}
上記の情報を設定したら、ファイルを保存して閉じます。
セカンダリロードバランサーの構成の作成
次に、セカンダリロードバランサーでコンパニオンスクリプトを作成します。 セカンダリサーバーの/etc/keepalived/keepalived.confでファイルを開きます。
- sudo nano /etc/keepalived/keepalived.conf
内部では、使用するスクリプトはプライマリサーバーのスクリプトとほぼ同じです。 変更する必要がある項目は次のとおりです。
state:選択が行われる前にノードがバックアップ状態に初期化されるように、これをセカンダリサーバーで「バックアップ」に変更する必要があります。priority:これはプライマリサーバーよりも低い値に設定する必要があります。 このガイドでは、値「100」を使用します。unicast_src_ip:これはセカンダリサーバーのプライベートIPアドレスである必要があります。unicast_peer:これにはプライマリサーバーのプライベートIPアドレスが含まれている必要があります。
これらの値を変更すると、セカンダリサーバーのスクリプトは次のようになります。
vrrp_script chk_haproxy {
script "pidof haproxy"
interval 2
}
vrrp_instance VI_1 {
interface eth1
state BACKUP
priority 100
virtual_router_id 33
unicast_src_ip secondary_private_IP
unicast_peer {
primary_private_IP
}
authentication {
auth_type PASS
auth_pass password
}
track_script {
chk_haproxy
}
notify_master /etc/keepalived/master.sh
}
スクリプトを入力して適切な値を変更したら、ファイルを保存して閉じます。
フローティングIP移行スクリプトを作成する
次に、ローカルkeepalivedインスタンスがマスターサーバーになるたびに、フローティングIPアドレスを現在のドロップレットに再割り当てするために使用できるスクリプトのペアを作成する必要があります。
フローティングIP割り当てスクリプトをダウンロードする
まず、DigitalOcean APIを使用してフローティングIPアドレスをドロップレットに再割り当てするために使用できる汎用Pythonスクリプト( DigitalOceanコミュニティマネージャーによって記述された)をダウンロードします。 このファイルを/usr/local/binディレクトリにダウンロードする必要があります。
- cd /usr/local/bin
- sudo curl -LO http://do.co/assign-ip
このスクリプトを使用すると、次のコマンドを実行して既存のフローティングIPを再割り当てできます。
- python /usr/local/bin/assign-ip floating_ip droplet_ID
これは、DO_TOKENという環境変数がアカウントの有効なDigitalOceanAPIトークンに設定されている場合にのみ機能します。
DigitalOceanAPIトークンを作成する
上記のスクリプトを使用するには、アカウントにDigitalOceanAPIトークンを作成する必要があります。
コントロールパネルで、上部の「API」リンクをクリックします。 APIページの右側で、[新しいトークンを生成]をクリックします。

次のページで、トークンの名前を選択し、[トークンの生成]ボタンをクリックします。
APIページに、新しいトークンが表示されます。

トークンnowをコピーします。 セキュリティ上の理由から、後でこのトークンを再度表示する方法はありません。 このトークンを紛失した場合は、トークンを破棄して別のトークンを作成する必要があります。
インフラストラクチャのフローティングIPを構成する
次に、サーバーに使用するフローティングIPアドレスを作成して割り当てます。
DigitalOceanコントロールパネルで、[ネットワーク]タブをクリックし、[フローティングIP]ナビゲーション項目を選択します。 最初の割り当てのメニューからプライマリロードバランサーを選択します。
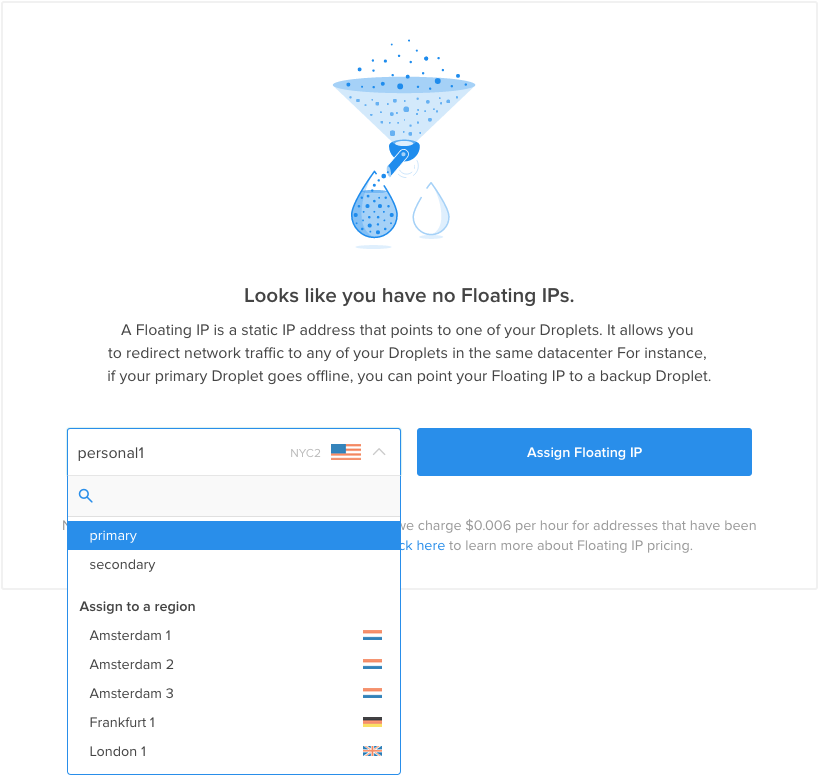
アカウントに新しいフローティングIPアドレスが作成され、指定されたドロップレットに割り当てられます。

WebブラウザでフローティングIPにアクセスすると、バックエンドWebサーバーの1つから提供されるデフォルトのNginxページが表示されます。
フローティングIPアドレスをコピーします。 以下のスクリプトでこの値が必要になります。
ラッパースクリプトを作成する
これで、正しいクレデンシャルを使用して/usr/local/bin/assign-ipスクリプトを呼び出すラッパースクリプトを作成するために必要なアイテムができました。
次のように入力して、ロードバランサーの両方にファイルを作成します。
- sudo nano /etc/keepalived/master.sh
内部では、作成したAPIトークンを保持するDO_TOKENという変数を割り当ててエクスポートすることから始めます。 その下に、フローティングIPアドレスを保持するIPという変数を割り当てることができます。
export DO_TOKEN='digitalocean_api_token'
IP='floating_ip_addr'
次に、curlを使用して、現在使用しているサーバーのドロップレットIDをメタデータサービスに要求します。 これは、IDという変数に割り当てられます。 また、このドロップレットに現在フローティングIPアドレスが割り当てられているかどうかも確認します。 そのリクエストの結果をHAS_FLOATING_IPという変数に保存します。
export DO_TOKEN='digitalocean_api_token'
IP='floating_ip_addr'
ID=$(curl -s http://169.254.169.254/metadata/v1/id)
HAS_FLOATING_IP=$(curl -s http://169.254.169.254/metadata/v1/floating_ip/ipv4/active)
これで、上記の変数を使用してassign-ipスクリプトを呼び出すことができます。 フローティングIPがまだドロップレットに関連付けられていない場合にのみスクリプトを呼び出します。 これにより、API呼び出しを最小限に抑え、マスターステータスがサーバー間で急速に切り替わる場合にAPIへのリクエストの競合を防ぐことができます。
フローティングIPですでに進行中のイベントがある場合を処理するために、assign-ipスクリプトを数回再試行します。 以下では、各呼び出しの間隔を3秒にして、スクリプトを10回実行しようとします。 フローティングIPの移動が成功すると、ループはすぐに終了します。
export DO_TOKEN='digitalocean_api_token'
IP='floating_ip_addr'
ID=$(curl -s http://169.254.169.254/metadata/v1/id)
HAS_FLOATING_IP=$(curl -s http://169.254.169.254/metadata/v1/floating_ip/ipv4/active)
if [ $HAS_FLOATING_IP = "false" ]; then
n=0
while [ $n -lt 10 ]
do
python /usr/local/bin/assign-ip $IP $ID && break
n=$((n+1))
sleep 3
done
fi
終了したら、ファイルを保存して閉じます。
ここで、keepalivedがスクリプトを呼び出せるように、スクリプトを実行可能にする必要があります。
- sudo chmod +x /etc/keepalived/master.sh
キープアライブサービスを起動し、フェイルオーバーをテストします
これで、keepalivedデーモンとそのすべてのコンパニオンスクリプトが完全に構成されているはずです。 次のように入力することで、両方のロードバランサーでサービスを開始できます。
- sudo start keepalived
サービスは各サーバーで起動し、そのピアに接続して、構成した共有シークレットで認証する必要があります。 各デーモンはローカルHAProxyプロセスを監視し、リモートkeepalivedプロセスからのシグナルをリッスンします。
現在フローティングIPアドレスが割り当てられているプライマリロードバランサーは、各バックエンドNginxサーバーに順番にリクエストを送信します。 通常適用されるいくつかの単純なセッションスティッキネスがあり、Webブラウザーを介して要求を行うときに同じバックエンドを取得する可能性が高くなります。
プライマリロードバランサーでHAProxyをオフにするだけで、簡単な方法でフェイルオーバーをテストできます。
- sudo service haproxy stop
ブラウザでフローティングIPアドレスにアクセスすると、ページが見つからなかったことを示すエラーが一時的に発生する場合があります。
http://floating_IP_addr
ページを数回更新すると、すぐにデフォルトのNginxページが返されます。
HAProxyサービスはプライマリロードバランサーでまだダウンしているため、これはセカンダリロードバランサーが引き継いだことを示しています。 keepalivedを使用して、セカンダリサーバーはサービスの中断が発生したことを判別できました。 次に、「マスター」状態に移行し、DigitalOceanAPIを使用してフローティングIPを要求しました。
これで、プライマリロードバランサーでHAProxyを再度起動できます。
- sudo service haproxy start
プライマリロードバランサーは、フローティングIPアドレスの制御をすぐに回復しますが、これはユーザーにはかなり透過的である必要があります。
移行の視覚化
ロードバランサー間の移行をより適切に視覚化するために、移行中にサーバーログの一部を監視できます。
使用されているプロキシサーバーに関する情報はクライアントに返されないため、ログを表示するのに最適な場所は、実際のバックエンドWebサーバーからです。 これらの各サーバーは、どのクライアントがアセットを要求するかについてのログを維持する必要があります。 Nginxサービスの観点からは、クライアントは実際のクライアントに代わってリクエストを行うロードバランサーです。
Webサーバーのログを追跡する
各バックエンドWebサーバーで、tail/var/log/nginx/access.logの場所を指定できます。 これにより、サーバーに対して行われた各リクエストが表示されます。 ロードバランサーはラウンドロビンローテーションを使用してトラフィックを均等に分割するため、各バックエンドWebサーバーは行われたリクエストの約半分を確認する必要があります。
幸い、クライアントアドレスはアクセスログの最初のフィールドです。 単純なawkコマンドを使用して値を抽出できます。 NginxWebサーバーの両方で以下を実行します。
- sudo tail -f /var/log/nginx/access.log | awk '{print $1;}'
これらは、ほとんど単一のアドレスを表示する可能性があります。
Output. . .
primary_lb_private_IP
primary_lb_private_IP
secondary_lb_private_IP
secondary_lb_private_IP
primary_lb_private_IP
primary_lb_private_IP
primary_lb_private_IP
primary_lb_private_IP
サーバーのIPアドレスを参照すると、これらは主にプライマリロードバランサーからのものであることがわかります。 HAProxyが実装する単純なセッションの粘着性のために、実際の配布は少し異なる可能性があることに注意してください。
tailコマンドを両方のWebサーバーで実行し続けます。
フローティングIPへのリクエストを自動化
これで、ローカルマシンで、2秒に1回フローティングIPアドレスでWebコンテンツをリクエストします。 これにより、ロードバランサーの変更が発生したことを簡単に確認できます。 ローカル端末で、次のように入力します(使用されているロードバランサーに関係なく同じである必要があるため、実際の応答は破棄されます)。
- while true; do curl -s -o /dev/null floating_IP; sleep 2; done
Webサーバーでは、新しいリクエストが届くのを確認し始める必要があります。 Webブラウザーを介して行われる要求とは異なり、単純なcurl要求は、同じセッションの粘着性を示しません。 バックエンドWebサーバーへのリクエストがより均等に分割されていることがわかります。
プライマリロードバランサーでHAProxyサービスを中断する
これで、プライマリロードバランサーのHAProxyサービスを再びシャットダウンできます。
- sudo service haproxy stop
数秒後、Webサーバーで、IPのリストがプライマリロードバランサーのプライベートIPアドレスからセカンダリロードバランサーのプライベートIPアドレスに移行するのを確認する必要があります。
Output. . .
primary_lb_private_IP
primary_lb_private_IP
primary_lb_private_IP
primary_lb_private_IP
primary_lb_private_IP
secondary_lb_private_IP
secondary_lb_private_IP
secondary_lb_private_IP
secondary_lb_private_IP
新しいリクエストはすべて、セカンダリロードバランサーから行われます。
次に、プライマリロードバランサーでHAProxyインスタンスを再起動します。
- sudo service haproxy start
クライアントリクエストが数秒以内にプライマリロードバランサーのプライベートIPアドレスに戻るのがわかります。
Output. . .
primary_lb_private_IP
primary_lb_private_IP
primary_lb_private_IP
primary_lb_private_IP
primary_lb_private_IP
secondary_lb_private_IP
secondary_lb_private_IP
secondary_lb_private_IP
secondary_lb_private_IP
primary_lb_private_IP
primary_lb_private_IP
primary_lb_private_IP
プライマリサーバーはフローティングIPアドレスの制御を取り戻し、インフラストラクチャのメインロードバランサーとしての役割を再開しました。
実際のクライアントIPアドレスをログに記録するようにNginxを構成する
ご覧のとおり、Nginxアクセスログには、すべてのクライアントリクエストが、最初にリクエストを行ったクライアントの実際のIPアドレスではなく、現在のロードバランサーのプライベートIPアドレスからのものであることが示されています(つまり、 ローカルマシン)。 ロードバランサーサーバーではなく、元のクライアントのIPアドレスをログに記録すると便利なことがよくあります。 これは、すべてのバックエンドWebサーバーでNginx構成にいくつかの変更を加えることで簡単に実現できます。
両方のWebサーバーで、nginx.confファイルをエディターで開きます。
- sudo nano /etc/nginx/nginx.conf
[ログ設定]セクション(httpブロック内)を見つけて、次の行を追加します。
log_format haproxy_log 'ProxyIP: $remote_addr - ClientIP: $http_x_forwarded_for - $remote_user [$time_local] ' '"$request" $status $body_bytes_sent "$http_referer" ' '"$http_user_agent"';
保存して終了。 これは、haproxy_logと呼ばれる新しいログ形式を指定します。これにより、$http_x_forwarded_for値(元の要求を行ったクライアントのIPアドレス)がデフォルトのアクセスログエントリに追加されます。 リバースプロキシロードバランサーのIPアドレスである$remote_addrも含まれています(つまり、 アクティブなロードバランサーサーバー)。
次に、この新しいログ形式を使用するには、デフォルトのサーバーブロックに行を追加する必要があります。
両方のWebサーバーで、defaultサーバー構成を開きます。
- sudo nano /etc/nginx/sites-available/default
serverブロック内(listenディレクティブのすぐ下が適切な場所です)に、次の行を追加します。
access_log /var/log/nginx/access.log haproxy_log;
保存して終了。 これにより、上記で作成したhaproxy_logログ形式を使用してアクセスログを書き込むようにNginxに指示されます。
両方のWebサーバーで、Nginxを再起動して、変更を有効にします。
- sudo service nginx restart
これで、Nginxアクセスログに、リクエストを行っているクライアントの実際のIPアドレスが含まれているはずです。 前のセクションで行ったように、アプリサーバーのログを追跡してこれを確認します。 ログエントリは次のようになります。
New Nginx access logs:. . .
ProxyIP: load_balancer_private_IP - ClientIP: local_machine_IP - - [05/Nov/2015:15:05:53 -0500] "GET / HTTP/1.1" 200 43 "-" "curl/7.43.0"
. . .
ログの見栄えが良ければ、準備は完了です。
結論
このガイドでは、可用性が高く、負荷分散されたインフラストラクチャをセットアップする完全なプロセスについて説明しました。 アクティブなHAProxyサーバーがバックエンド上のWebサーバーのプールに負荷を分散できるため、この構成は適切に機能します。 需要の拡大または縮小に応じて、このプールを簡単に拡張できます。
フローティングIPとkeepalived構成により、負荷分散レイヤーでの単一障害点が排除され、プライマリロードバランサーに完全な障害が発生した場合でもサービスが機能し続けることができます。 この構成はかなり柔軟性があり、HAProxyサーバーの背後に優先Webスタックを設定することで、独自のアプリケーション環境に適合させることができます。