序章
負荷分散は、複数のサーバーにワークロードを分散することにより、Webサイト、アプリケーション、データベース、およびその他のサービスのパフォーマンスと信頼性を向上させるために一般的に使用される高可用性インフラストラクチャの重要なコンポーネントです。
負荷分散のないWebインフラストラクチャは、次のようになります。
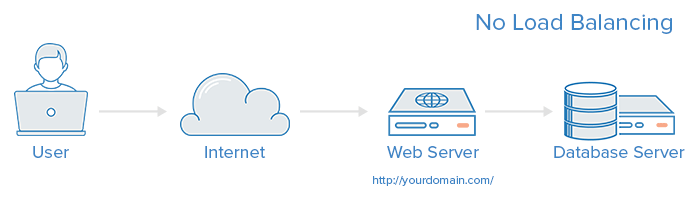

この例では、ユーザーはyourdomain.comでWebサーバーに直接接続します。 この単一のWebサーバーがダウンすると、ユーザーはWebサイトにアクセスできなくなります。 さらに、多くのユーザーが同時にサーバーにアクセスしようとして負荷を処理できない場合、ロード時間が遅くなったり、まったく接続できなくなったりする可能性があります。
この単一障害点は、バックエンドにロードバランサーと少なくとも1つの追加のWebサーバーを導入することで軽減できます。 通常、すべてのバックエンドサーバーは同一のコンテンツを提供するため、ユーザーはどのサーバーが応答するかに関係なく一貫したコンテンツを受信します。
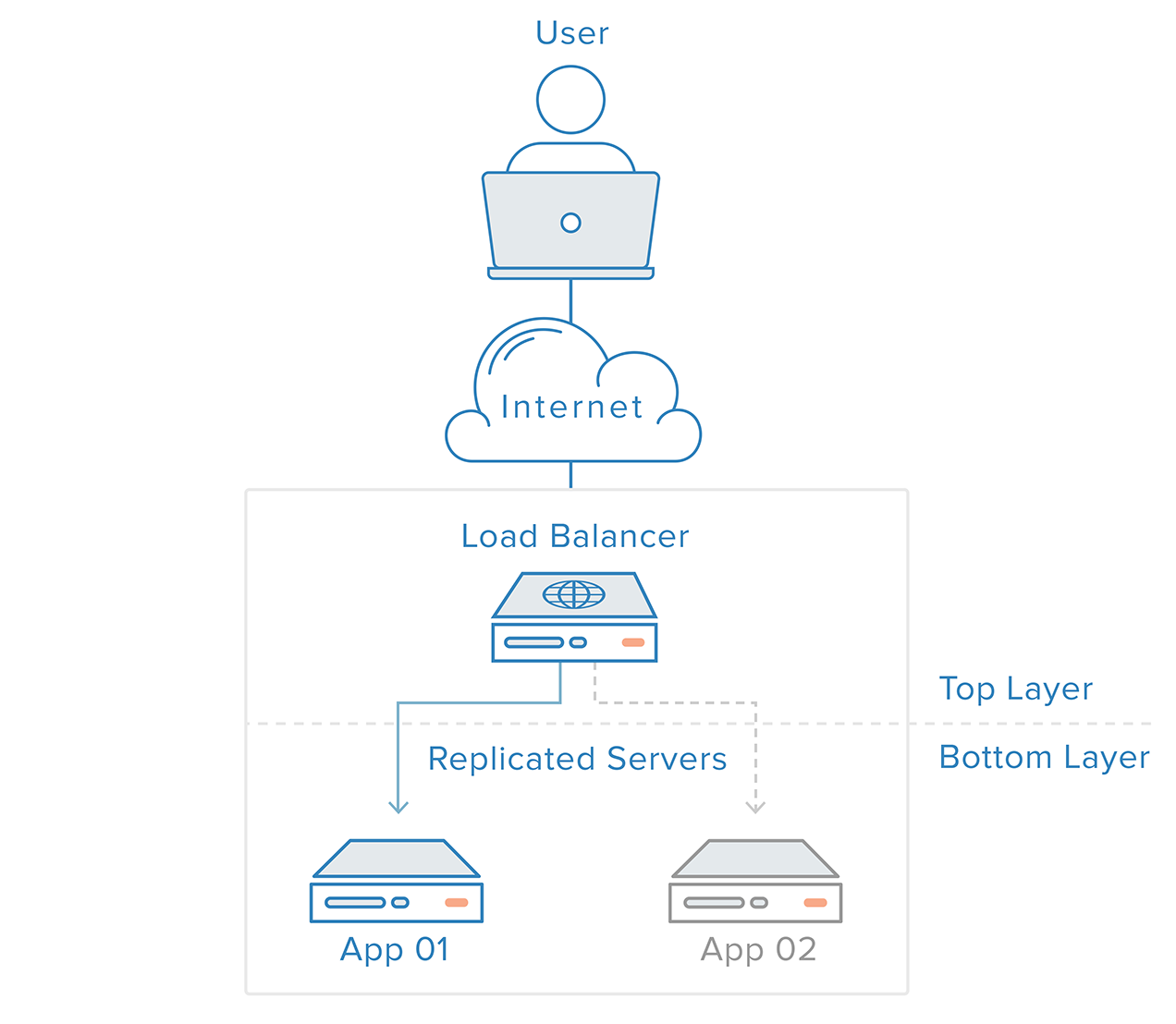

上記の例では、ユーザーはロードバランサーにアクセスします。ロードバランサーは、ユーザーのリクエストをバックエンドサーバーに転送し、バックエンドサーバーはユーザーのリクエストに直接応答します。 このシナリオでは、単一障害点はロードバランサー自体になります。 これは、2番目のロードバランサーを導入することで軽減できますが、その前に、ロードバランサーがどのように機能するかを調べてみましょう。
ロードバランサーはどのような種類のトラフィックを処理できますか?
ロードバランサーの管理者は、次の4つの主要なタイプのトラフィックの転送ルールを作成します。
- HTTP —標準のHTTPバランシングは、標準のHTTPメカニズムに基づいてリクエストを送信します。 ロードバランサーは、
X-Forwarded-For、X-Forwarded-Proto、およびX-Forwarded-Portヘッダーを設定して、元のリクエストに関する情報をバックエンドに提供します。 - HTTPS — HTTPSバランシングは、暗号化が追加されていることを除いて、HTTPバランシングと同じように機能します。 暗号化は2つの方法のいずれかで処理されます。バックエンドまで暗号化を維持するSSLパススルー、またはロードバランサーに復号化の負担をかけるがバックエンドへの暗号化されていないトラフィック。
- TCP — HTTPまたはHTTPSを使用しないアプリケーションの場合、TCPトラフィックのバランスを取ることもできます。 たとえば、データベースクラスターへのトラフィックをすべてのサーバーに分散させることができます。
- UDP —最近、一部のロードバランサーは、UDPを使用するDNSやsyslogdなどのコアインターネットプロトコルの負荷分散のサポートを追加しました。
これらの転送ルールは、ロードバランサー自体でプロトコルとポートを定義し、それらをロードバランサーがバックエンドでトラフィックをルーティングするために使用するプロトコルとポートにマップします。
ロードバランサーはどのようにバックエンドサーバーを選択しますか?
ロードバランサーは、2つの要素の組み合わせに基づいて、リクエストを転送するサーバーを選択します。 まず、選択できるサーバーが実際に要求に適切に応答していることを確認してから、事前構成されたルールを使用して、その正常なプールから選択します。
ヘルスチェック
ロードバランサーは、トラフィックを「正常な」バックエンドサーバーにのみ転送する必要があります。 バックエンドサーバーの状態を監視するために、ヘルスチェックは、サーバーがリッスンしていることを確認するために、転送ルールで定義されたプロトコルとポートを使用してバックエンドサーバーへの接続を定期的に試みます。 サーバーがヘルスチェックに失敗したために要求を処理できない場合、サーバーはプールから自動的に削除され、ヘルスチェックに再度応答するまでトラフィックはサーバーに転送されません。
負荷分散アルゴリズム
使用される負荷分散アルゴリズムによって、バックエンド上の正常なサーバーのどれが選択されるかが決まります。 一般的に使用されるアルゴリズムのいくつかは次のとおりです。
ラウンドロビン—ラウンドロビンは、サーバーが順番に選択されることを意味します。 ロードバランサーは、最初のリクエストに対してリストの最初のサーバーを選択し、リストを順番に下に移動し、最後に到達したときに最初からやり直します。
最小接続—最小接続は、ロードバランサーが接続数が最も少ないサーバーを選択することを意味し、トラフィックによってセッションが長くなる場合に推奨されます。
Source — Sourceアルゴリズムを使用すると、ロードバランサーは、訪問者のIPアドレスなど、要求の送信元IPのハッシュに基づいて使用するサーバーを選択します。 この方法により、特定のユーザーが一貫して同じサーバーに接続できるようになります。
管理者が利用できるアルゴリズムは、使用している特定の負荷分散テクノロジーによって異なります。
ロードバランサーはどのように状態を処理しますか?
一部のアプリケーションでは、ユーザーが同じバックエンドサーバーに接続し続ける必要があります。 ソースアルゴリズムは、クライアントのIP情報に基づいてアフィニティを作成します。 Webアプリケーションレベルでこれを実現する別の方法は、スティッキーセッションを使用することです。この場合、ロードバランサーがCookieを設定し、そのセッションからのすべてのリクエストが同じ物理サーバーに送信されます。
冗長ロードバランサー
単一障害点としてロードバランサーを削除するには、2番目のロードバランサーを最初のロードバランサーに接続してクラスターを形成し、それぞれが他のロードバランサーの状態を監視します。 それぞれが、障害の検出と回復を同等に行うことができます。
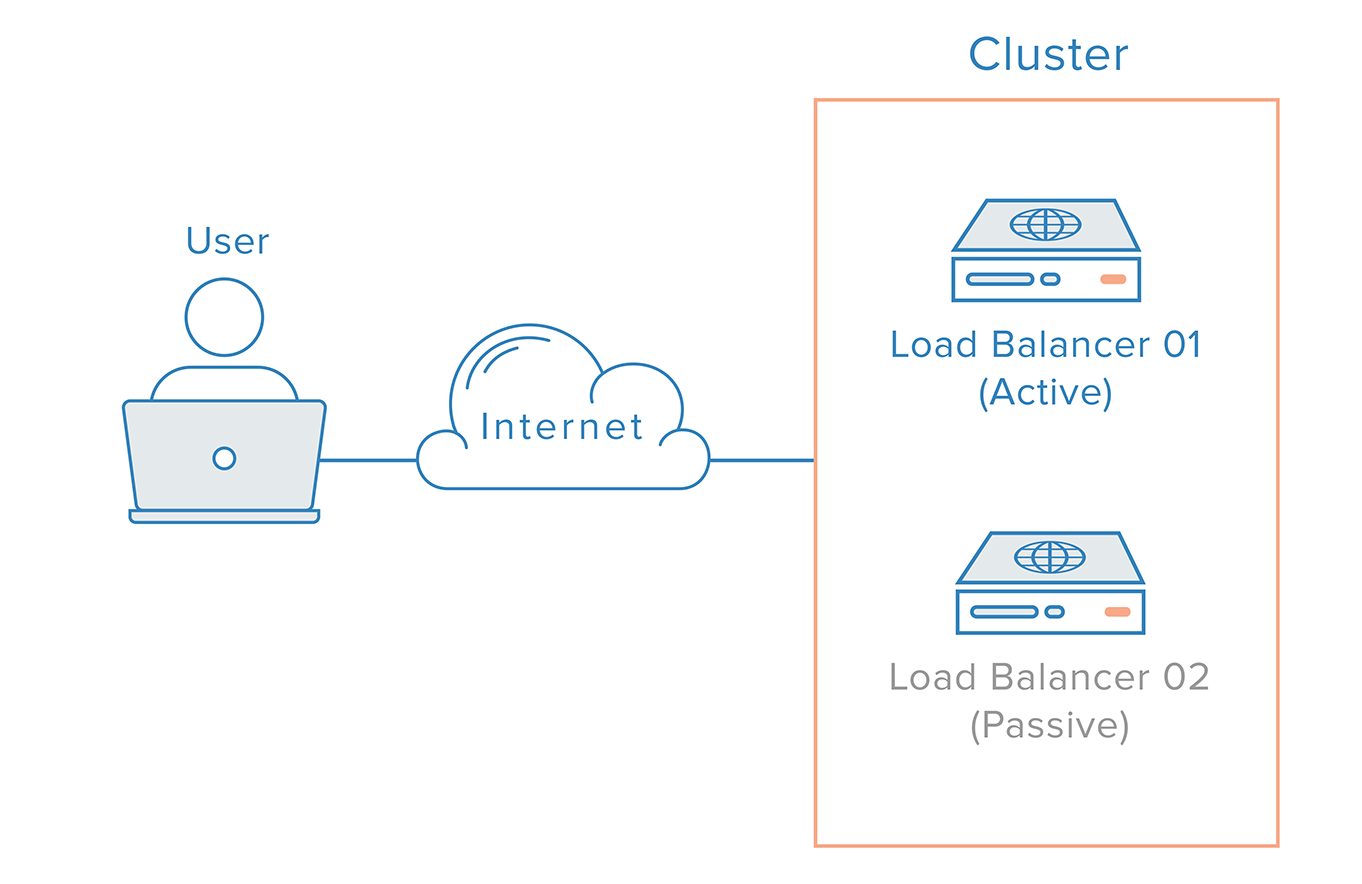

メインのロードバランサーに障害が発生した場合、DNSはユーザーを2番目のロードバランサーに誘導する必要があります。 DNSの変更は、インターネット上で伝播され、このフェイルオーバーを自動化するのにかなりの時間がかかる可能性があるため、多くの管理者は、フローティングIPなどの柔軟なIPアドレスの再マッピングを可能にするシステムを使用します。 オンデマンドIPアドレスの再マッピングは、必要なときに簡単に再マッピングできる静的IPアドレスを提供することにより、DNS変更に固有の伝播とキャッシュの問題を排除します。 ドメイン名は同じIPアドレスに関連付けたままにすることができますが、IPアドレス自体はサーバー間で移動されます。
これは、フローティングIPを使用する高可用性インフラストラクチャがどのように見えるかを示しています。


結論
この記事では、ロードバランサーの概念の概要と、それらが一般的にどのように機能するかについて説明しました。 特定の負荷分散テクノロジーの詳細については、以下を参照してください。
DigitalOceanの負荷分散サービス
- 最初のDigitalOceanロードバランサーを作成する方法
- DigitalOceanロードバランサーでSSLパススルーを構成する方法
- DigitalOceanロードバランサーでSSLターミネーションを構成する方法
- DigitalOceanロードバランサーを使用してTCPトラフィックのバランスをとる方法
HAProxy
- HAProxyと負荷分散の概念の概要
- Ubuntu14.04でキープアライブおよびフローティングIPを使用して高可用性HAProxyサーバーをセットアップする方法
- HAProxyを使用したWordPressの負荷分散
