Ubuntu 20.04にElasticsearch、Logstash、およびKibana(Elastic Stack)をインストールする方法
序章
Elastic Stack(以前は ELK Stack と呼ばれていました)は、 Elastic によって生成されたオープンソースソフトウェアのコレクションであり、任意のソースから生成されたログを検索、分析、および視覚化できます。任意の形式、集中ログとして知られる手法。 一元化されたログは、すべてのログを1か所で検索できるため、サーバーまたはアプリケーションの問題を特定する場合に役立ちます。 また、特定の時間枠でログを相互に関連付けることにより、複数のサーバーにまたがる問題を特定できるので便利です。
ElasticStackには4つの主要なコンポーネントがあります。
- Elasticsearch :収集されたすべてのデータを保存する分散型RESTful検索エンジン。
- Logstash :着信データをElasticsearchに送信するElasticStackのデータ処理コンポーネント。
- Kibana :ログを検索および視覚化するためのWebインターフェイス。
- Beats :数百または数千のマシンからLogstashまたはElasticsearchにデータを送信できる軽量の単一目的のデータシッパー。
このチュートリアルでは、 ElasticStackをUbuntu20.04サーバーにインストールします。 ログとファイルの転送と集中化に使用されるBeatであるFilebeatを含む、Elastic Stackのすべてのコンポーネントをインストールし、システムログを収集して視覚化するように構成する方法を学習します。 さらに、Kibanaは通常localhostでのみ使用できるため、 Nginx を使用してプロキシし、Webブラウザーからアクセスできるようにします。 これらすべてのコンポーネントを単一のサーバーにインストールします。これをElasticStackサーバーと呼びます。
注:Elastic Stackをインストールするときは、スタック全体で同じバージョンを使用する必要があります。 このチュートリアルでは、スタック全体の最新バージョン(この記事の執筆時点では、Elasticsearch 7.7.1、Kibana 7.7.1、Logstash 7.7.1、およびFilebeat 7.7.1)をインストールします。
前提条件
このチュートリアルを完了するには、次のものが必要です。
-
ルート以外のsudoユーザーでセットアップされた4GBのRAMと2つのCPUを備えたUbuntu20.04サーバー。 これは、 Ubuntu 20.04でのサーバーの初期設定に従うことで実現できます。このチュートリアルでは、Elasticsearchの実行に必要な最小限のCPUとRAMを使用します。 Elasticsearchサーバーに必要なCPU、RAM、およびストレージの量は、予想されるログの量によって異なることに注意してください。
-
OpenJDK11がインストールされています。 [デフォルトのJRE/JDKのインストール]( ../how-to-install-java-with-apt-on-ubuntu-20-04#installing)のセクションを参照してください。 -ガイドの-the-default-jrejdk Ubuntu20.04にAptを使用してJavaをインストールしてこれを設定する方法。
-
Nginxがサーバーにインストールされています。これについては、このガイドの後半でKibanaのリバースプロキシとして構成します。 これを設定するには、 Ubuntu20.04にNginxをインストールする方法に関するガイドに従ってください。
さらに、Elastic Stackは、許可されていないユーザーにアクセスさせたくないサーバーに関する貴重な情報にアクセスするために使用されるため、TLS/SSL証明書をインストールしてサーバーを安全に保つことが重要です。 これはオプションですが、強くお勧めします。
ただし、このガイドの過程で最終的にNginxサーバーブロックに変更を加えるため、このチュートリアルの2番目の最後にある Ubuntu20.04で暗号化しようガイドを完了する方が理にかなっていると思われます。ステップ。 そのことを念頭に置いて、サーバーでLet’s Encryptを構成する場合は、その前に次のことを行う必要があります。
-
完全修飾ドメイン名(FQDN)。 このチュートリアルでは、全体を通して
your_domainを使用します。 Namecheap でドメイン名を購入するか、 Freenom で無料でドメイン名を取得するか、選択したドメイン登録事業者を使用できます。 -
次の両方のDNSレコードがサーバー用に設定されています。 それらを追加する方法の詳細については、このDigitalOceanDNSの紹介に従ってください。
- サーバーのパブリックIPアドレスを指す
your_domainのAレコード。 - サーバーのパブリックIPアドレスを指す
www.your_domainのAレコード。
- サーバーのパブリックIPアドレスを指す
ステップ1—Elasticsearchのインストールと設定
Elasticsearchコンポーネントは、Ubuntuのデフォルトのパッケージリポジトリでは利用できません。 ただし、Elasticのパッケージソースリストを追加した後、APTを使用してインストールできます。
システムをパッケージのなりすましから保護するために、すべてのパッケージはElasticsearch署名キーで署名されています。 キーを使用して認証されたパッケージは、パッケージマネージャーによって信頼されていると見なされます。 このステップでは、Elasticsearchをインストールするために、Elasticsearchの公開GPGキーをインポートし、Elasticパッケージのソースリストを追加します。
まず、URLを使用してデータを転送するためのコマンドラインツールであるcURLを使用して、Elasticsearchの公開GPGキーをAPTにインポートします。 引数-fsSLを使用して、すべての進行状況と発生する可能性のあるエラー(サーバー障害を除く)をサイレントにし、リダイレクトされた場合にcURLが新しい場所でリクエストを行えるようにしていることに注意してください。 cURLコマンドの出力をapt-keyプログラムにパイプします。これにより、パブリックGPGキーがAPTに追加されます。
- curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
次に、Elasticソースリストをsources.list.dディレクトリに追加します。ここで、APTは新しいソースを検索します。
- echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
次に、パッケージリストを更新して、APTが新しいElasticソースを読み取るようにします。
- sudo apt update
次に、次のコマンドを使用してElasticsearchをインストールします。
- sudo apt install elasticsearch
これでElasticsearchがインストールされ、構成する準備が整いました。 お好みのテキストエディタを使用して、Elasticsearchのメイン設定ファイルelasticsearch.ymlを編集します。 ここでは、nanoを使用します。
- sudo nano /etc/elasticsearch/elasticsearch.yml
注: Elasticsearchの構成ファイルはYAML形式です。つまり、インデント形式を維持する必要があります。 このファイルを編集するときは、余分なスペースを追加しないでください。
elasticsearch.ymlファイルは、クラスター、ノード、パス、メモリ、ネットワーク、検出、およびゲートウェイの構成オプションを提供します。 これらのオプションのほとんどはファイルで事前構成されていますが、必要に応じて変更できます。 単一サーバー構成のデモンストレーションの目的で、ネットワークホストの設定のみを調整します。
Elasticsearchは、ポート9200であらゆる場所からのトラフィックをリッスンします。 Elasticsearchインスタンスへの外部アクセスを制限して、部外者がデータを読み取ったり、[REST API]( https://en.wikipedia.org/wiki/Representational_state_transfer )を介してElasticsearchクラスターをシャットダウンしたりしないようにする必要があります。 )。 アクセスを制限してセキュリティを強化するには、network.hostを指定する行を見つけてコメントを外し、その値を次のようにlocalhostに置き換えます。
. . .
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: localhost
. . .
ElasticsearchがすべてのインターフェースとバインドされたIPでリッスンするようにlocalhostを指定しました。 特定のインターフェースでのみリッスンする場合は、localhostの代わりにIPを指定できます。 elasticsearch.ymlを保存して閉じます。 nanoを使用している場合は、CTRL+X、Y、ENTERの順に押すと使用できます。
これらは、Elasticsearchを使用するために開始できる最小設定です。 これで、Elasticsearchを初めて起動できます。
systemctlでElasticsearchサービスを開始します。 Elasticsearchを起動するまでしばらくお待ちください。 そうしないと、接続できないというエラーが発生する可能性があります。
- sudo systemctl start elasticsearch
次に、次のコマンドを実行して、サーバーが起動するたびにElasticsearchを起動できるようにします。
- sudo systemctl enable elasticsearch
HTTPリクエストを送信することで、Elasticsearchサービスが実行されているかどうかをテストできます。
- curl -X GET "localhost:9200"
次のような、ローカルノードに関するいくつかの基本情報を示す応答が表示されます。
Output{
"name" : "Elasticsearch",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "qqhFHPigQ9e2lk-a7AvLNQ",
"version" : {
"number" : "7.7.1",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "ef48eb35cf30adf4db14086e8aabd07ef6fb113f",
"build_date" : "2020-03-26T06:34:37.794943Z",
"build_snapshot" : false,
"lucene_version" : "8.5.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Elasticsearchが稼働しているので、ElasticStackの次のコンポーネントであるKibanaをインストールしましょう。
ステップ2—Kibanaダッシュボードのインストールと構成
公式ドキュメントによると、Elasticsearchをインストールした後にのみKibanaをインストールする必要があります。 この順序でインストールすると、各製品が依存するコンポーネントが正しく配置されます。
前の手順でElasticパッケージソースをすでに追加しているため、aptを使用してElasticStackの残りのコンポーネントをインストールできます。
- sudo apt install kibana
次に、Kibanaサービスを有効にして開始します。
- sudo systemctl enable kibana
- sudo systemctl start kibana
Kibanaはlocalhostでのみリッスンするように構成されているため、外部アクセスを許可するためにリバースプロキシを設定する必要があります。 この目的のためにNginxを使用します。これは、サーバーにすでにインストールされているはずです。
まず、opensslコマンドを使用して、KibanaWebインターフェイスへのアクセスに使用する管理用Kibanaユーザーを作成します。 例として、このアカウントにkibanaadminという名前を付けますが、セキュリティを強化するために、推測が難しい非標準の名前をユーザーに選択することをお勧めします。
次のコマンドは、管理用Kibanaユーザーとパスワードを作成し、それらをhtpasswd.usersファイルに保存します。 このユーザー名とパスワードを要求するようにNginxを構成し、このファイルを一時的に読み取ります。
- echo "kibanaadmin:`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.users
プロンプトでパスワードを入力して確認します。 Kibana Webインターフェースにアクセスするために必要になるため、このログインを覚えておくか、メモしてください。
次に、Nginxサーバーブロックファイルを作成します。 例として、このファイルをyour_domainと呼びますが、よりわかりやすい名前を付けると役立つ場合があります。 たとえば、このサーバーにFQDNとDNSレコードを設定している場合は、FQDNにちなんでこのファイルに名前を付けることができます。
nanoまたはお好みのテキストエディタを使用して、Nginxサーバーブロックファイルを作成します。
- sudo nano /etc/nginx/sites-available/your_domain
次のコードブロックをファイルに追加します。サーバーのFQDNまたはパブリックIPアドレスと一致するようにyour_domainを更新してください。 このコードは、サーバーのHTTPトラフィックをlocalhost:5601でリッスンしているKibanaアプリケーションに転送するようにNginxを構成します。 さらに、htpasswd.usersファイルを読み取り、基本認証を要求するようにNginxを構成します。
前提条件のNginxチュートリアルを最後まで実行した場合は、このファイルを既に作成し、コンテンツを入力している可能性があることに注意してください。 その場合は、以下を追加する前に、ファイル内の既存のコンテンツをすべて削除してください。
server {
listen 80;
server_name your_domain;
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/htpasswd.users;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
終了したら、ファイルを保存して閉じます。
次に、sites-enabledディレクトリへのシンボリックリンクを作成して、新しい構成を有効にします。 Nginxの前提条件で同じ名前のサーバーブロックファイルを既に作成している場合は、次のコマンドを実行する必要はありません。
- sudo ln -s /etc/nginx/sites-available/your_domain /etc/nginx/sites-enabled/your_domain
次に、構成に構文エラーがないか確認します。
- sudo nginx -t
出力にエラーが報告された場合は、戻って、構成ファイルに配置したコンテンツが正しく追加されていることを再確認してください。 出力にsyntax is okが表示されたら、先に進んでNginxサービスを再起動します。
- sudo systemctl reload nginx
サーバーの初期設定ガイドに従っている場合は、UFWファイアウォールを有効にする必要があります。 Nginxへの接続を許可するには、次のように入力してルールを調整できます。
- sudo ufw allow 'Nginx Full'
注:前提条件のNginxチュートリアルに従った場合、ファイアウォールを通過するNginx HTTPプロファイルを許可するUFWルールを作成した可能性があります。 Nginx Fullプロファイルでは、ファイアウォールを通過するHTTPトラフィックとHTTPSトラフィックの両方が許可されるため、前提条件のチュートリアルで作成したルールを安全に削除できます。 次のコマンドでこれを行います。
- sudo ufw delete allow 'Nginx HTTP'
これで、FQDNまたはElasticStackサーバーのパブリックIPアドレスを介してKibanaにアクセスできます。 次のアドレスに移動し、プロンプトが表示されたらログイン資格情報を入力することで、Kibanaサーバーのステータスページを確認できます。
http://your_domain/status
このステータスページには、サーバーのリソース使用状況に関する情報が表示され、インストールされているプラグインが一覧表示されます。
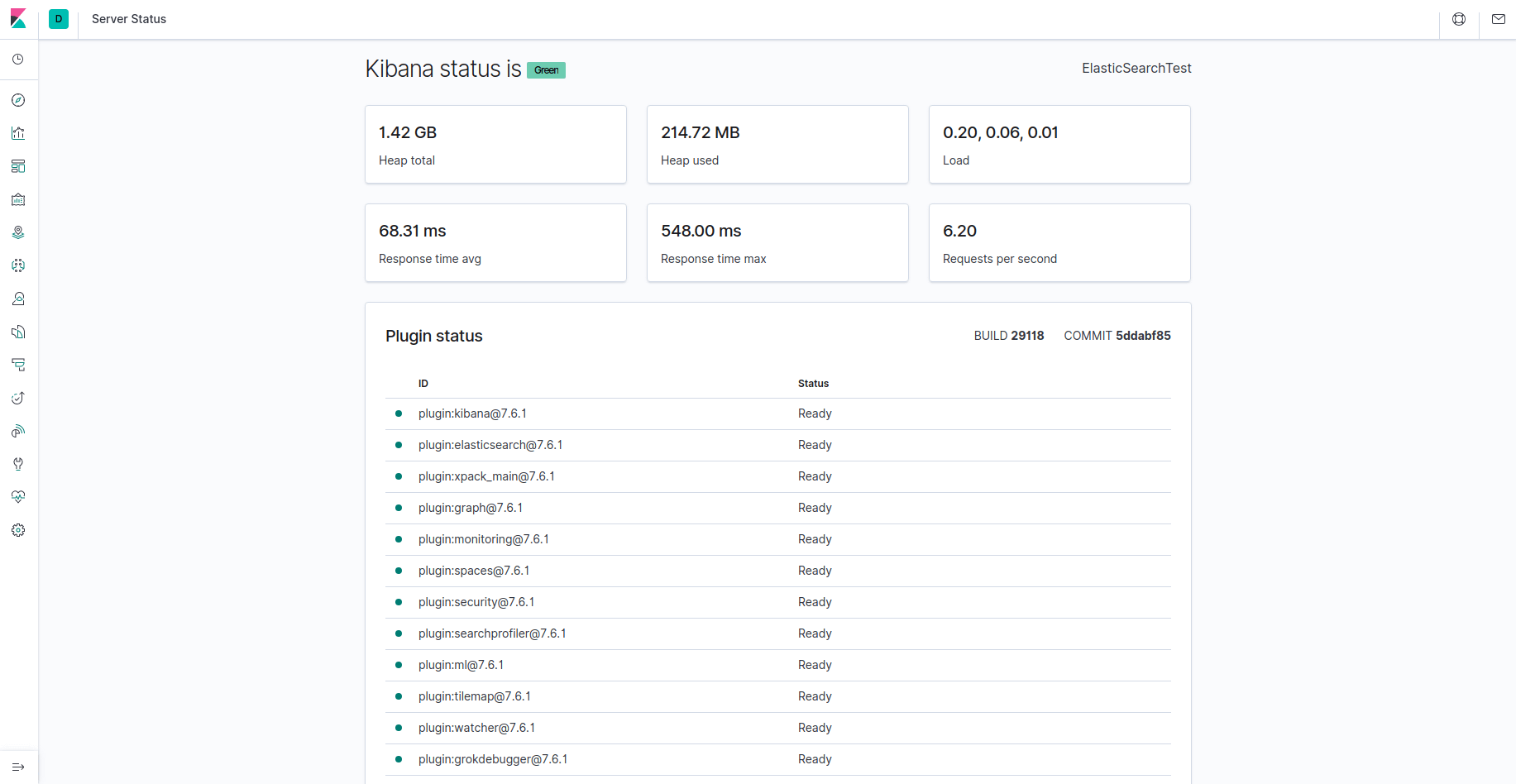
注:「前提条件」セクションで説明したように、サーバーでSSL/TLSを有効にすることをお勧めします。 今すぐLet’sEncrypt ガイドに従って、Ubuntu20.04でNginxの無料SSL証明書を取得できます。 SSL / TLS証明書を取得したら、戻ってこのチュートリアルを完了することができます。
Kibanaダッシュボードが構成されたので、次のコンポーネントであるLogstashをインストールしましょう。
ステップ3—Logstashのインストールと構成
BeatsがデータをElasticsearchデータベースに直接送信することは可能ですが、Logstashを使用してデータを処理するのが一般的です。 これにより、さまざまなソースからデータを収集し、それを共通の形式に変換して、別のデータベースにエクスポートするための柔軟性が高まります。
次のコマンドでLogstashをインストールします。
- sudo apt install logstash
Logstashをインストールした後、構成に進むことができます。 Logstashの構成ファイルは、/etc/logstash/conf.dディレクトリにあります。 構成構文の詳細については、Elasticが提供する構成リファレンスを確認してください。 ファイルを構成するとき、Logstashを、一方の端でデータを取り込み、何らかの方法でデータを処理し、その宛先(この場合、宛先はElasticsearch)に送信するパイプラインと考えると便利です。 Logstashパイプラインには、inputとoutputの2つの必須要素と、filterの1つのオプション要素があります。 入力プラグインはソースからのデータを消費し、フィルタープラグインはデータを処理し、出力プラグインはデータを宛先に書き込みます。
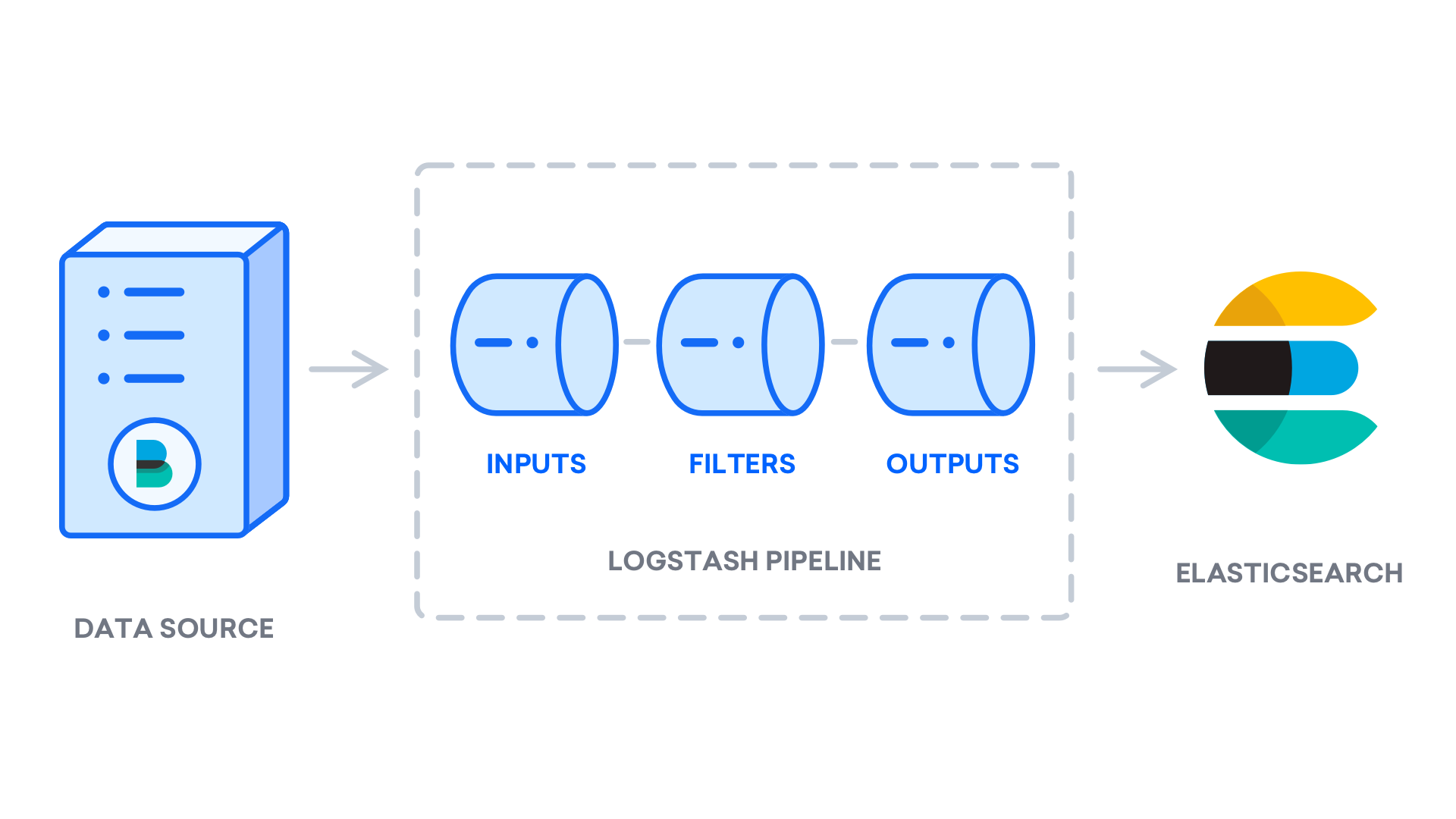
02-beats-input.confという構成ファイルを作成します。ここで、Filebeat入力を設定します。
- sudo nano /etc/logstash/conf.d/02-beats-input.conf
次のinput構成を挿入します。 これは、TCPポート5044でリッスンするbeats入力を指定します。
input {
beats {
port => 5044
}
}
ファイルを保存して閉じます。
次に、30-elasticsearch-output.confという構成ファイルを作成します。
- sudo nano /etc/logstash/conf.d/30-elasticsearch-output.conf
次のoutput構成を挿入します。 基本的に、この出力は、localhost:9200で実行されているElasticsearchのBeatsデータを、使用されたBeatにちなんで名付けられたインデックスに保存するようにLogstashを構成します。 このチュートリアルで使用されるビートはFilebeatです。
output {
if [@metadata][pipeline] {
elasticsearch {
hosts => ["localhost:9200"]
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
pipeline => "%{[@metadata][pipeline]}"
}
} else {
elasticsearch {
hosts => ["localhost:9200"]
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
}
}
ファイルを保存して閉じます。
次のコマンドを使用して、Logstash構成をテストします。
- sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t
構文エラーがない場合、出力には数秒後にConfig Validation Result: OK. Exiting Logstashが表示されます。 出力にこれが表示されない場合は、出力にエラーがないか確認し、構成を更新して修正してください。 OpenJDKから警告が表示されますが、問題が発生することはなく、無視してかまいません。
構成テストが成功した場合は、Logstashを起動して有効にし、構成の変更を有効にします。
- sudo systemctl start logstash
- sudo systemctl enable logstash
Logstashが正しく実行され、完全に構成されたので、Filebeatをインストールしましょう。
ステップ4—Filebeatのインストールと構成
Elastic Stackは、Beatsと呼ばれるいくつかの軽量データシッパーを使用して、さまざまなソースからデータを収集し、LogstashまたはElasticsearchに転送します。 現在Elasticから入手できるBeatsは次のとおりです。
- Filebeat :ログファイルを収集して送信します。
- Metricbeat :システムとサービスからメトリックを収集します。
- Packetbeat :ネットワークデータを収集して分析します。
- Winlogbeat :Windowsイベントログを収集します。
- Auditbeat :Linux監査フレームワークデータを収集し、ファイルの整合性を監視します。
- Heartbeat :アクティブプロービングを使用してサービスの可用性を監視します。
このチュートリアルでは、Filebeatを使用してローカルログをElasticStackに転送します。
aptを使用してFilebeatをインストールします。
- sudo apt install filebeat
次に、Logstashに接続するようにFilebeatを構成します。 ここでは、Filebeatに付属している設定ファイルの例を変更します。
Filebeat構成ファイルを開きます。
- sudo nano /etc/filebeat/filebeat.yml
注: Elasticsearchと同様に、Filebeatの構成ファイルはYAML形式です。 これは、適切なインデントが重要であることを意味するため、これらの手順に示されているのと同じ数のスペースを使用するようにしてください。
Filebeatは多数の出力をサポートしていますが、通常はイベントを直接ElasticsearchまたはLogstashに送信して追加の処理を行うだけです。 このチュートリアルでは、Logstashを使用して、Filebeatによって収集されたデータに対して追加の処理を実行します。 FilebeatはElasticsearchに直接データを送信する必要がないので、その出力を無効にしましょう。 これを行うには、output.elasticsearchセクションを見つけて、次の行の前に#を付けてコメントアウトします。
...
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
...
次に、output.logstashセクションを構成します。 #を削除して、output.logstash:とhosts: ["localhost:5044"]の行のコメントを解除します。 これにより、先にLogstash入力を指定したポートであるポート5044でElasticStackサーバーのLogstashに接続するようにFilebeatが構成されます。
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]
ファイルを保存して閉じます。
Filebeatの機能は、Filebeatモジュールで拡張できます。 このチュートリアルでは、 system モジュールを使用します。このモジュールは、一般的なLinuxディストリビューションのシステムロギングサービスによって作成されたログを収集して解析します。
それを有効にしましょう:
- sudo filebeat modules enable system
次のコマンドを実行すると、有効なモジュールと無効なモジュールのリストが表示されます。
- sudo filebeat modules list
次のようなリストが表示されます。
OutputEnabled:
system
Disabled:
apache2
auditd
elasticsearch
icinga
iis
kafka
kibana
logstash
mongodb
mysql
nginx
osquery
postgresql
redis
traefik
デフォルトでは、Filebeatはsyslogおよび許可ログにデフォルトのパスを使用するように構成されています。 このチュートリアルの場合、構成を変更する必要はありません。 モジュールのパラメータは、/etc/filebeat/modules.d/system.yml構成ファイルで確認できます。
次に、Filebeat取り込みパイプラインを設定する必要があります。このパイプラインは、logstashを介してelasticsearchに送信する前にログデータを解析します。 システムモジュールの取り込みパイプラインをロードするには、次のコマンドを入力します。
- sudo filebeat setup --pipelines --modules system
次に、インデックステンプレートをElasticsearchにロードします。 Elasticsearch index は、同様の特性を持つドキュメントのコレクションです。 インデックスは名前で識別されます。名前は、インデックス内でさまざまな操作を実行するときにインデックスを参照するために使用されます。 インデックステンプレートは、新しいインデックスが作成されるときに自動的に適用されます。
テンプレートをロードするには、次のコマンドを使用します。
- sudo filebeat setup --index-management -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]'
OutputIndex setup finished.
Filebeatには、KibanaでFilebeatデータを視覚化できるサンプルKibanaダッシュボードがパッケージ化されています。 ダッシュボードを使用する前に、インデックスパターンを作成し、ダッシュボードをKibanaにロードする必要があります。
ダッシュボードが読み込まれると、FilebeatはElasticsearchに接続してバージョン情報を確認します。 Logstashが有効になっているときにダッシュボードをロードするには、Logstash出力を無効にし、Elasticsearch出力を有効にする必要があります。
- sudo filebeat setup -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601
次のような出力が表示されます。
OutputOverwriting ILM policy is disabled. Set `setup.ilm.overwrite:true` for enabling.
Index setup finished.
Loading dashboards (Kibana must be running and reachable)
Loaded dashboards
Setting up ML using setup --machine-learning is going to be removed in 8.0.0. Please use the ML app instead.
See more: https://www.elastic.co/guide/en/elastic-stack-overview/current/xpack-ml.html
Loaded machine learning job configurations
Loaded Ingest pipelines
これで、Filebeatを起動して有効にできます。
- sudo systemctl start filebeat
- sudo systemctl enable filebeat
Elastic Stackを正しく設定すると、Filebeatはsyslogと認証ログのLogstashへの送信を開始し、LogstashはそのデータをElasticsearchにロードします。
Elasticsearchが実際にこのデータを受信していることを確認するには、次のコマンドでFilebeatインデックスをクエリします。
- curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty'
次のような出力が表示されます。
Output...
{
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4040,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "filebeat-7.7.1-2020.06.04",
"_type" : "_doc",
"_id" : "FiZLgXIB75I8Lxc9ewIH",
"_score" : 1.0,
"_source" : {
"cloud" : {
"provider" : "digitalocean",
"instance" : {
"id" : "194878454"
},
"region" : "nyc1"
},
"@timestamp" : "2020-06-04T21:45:03.995Z",
"agent" : {
"version" : "7.7.1",
"type" : "filebeat",
"ephemeral_id" : "cbcefb9a-8d15-4ce4-bad4-962a80371ec0",
"hostname" : "june-ubuntu-20-04-elasticstack",
"id" : "fbd5956f-12ab-4227-9782-f8f1a19b7f32"
},
...
出力に合計ヒット数が0と表示されている場合、Elasticsearchは検索したインデックスの下にログをロードしていないため、セットアップでエラーがないか確認する必要があります。 期待どおりの出力が得られたら、次のステップに進みます。このステップでは、Kibanaのダッシュボードの一部をナビゲートする方法を説明します。
ステップ5—Kibanaダッシュボードを探索する
以前にインストールしたKibanaWebインターフェースに戻りましょう。
Webブラウザーで、ElasticStackサーバーのFQDNまたはパブリックIPアドレスに移動します。 手順2で定義したログイン資格情報を入力すると、Kibanaのホームページが表示されます。
左側のナビゲーションバーにあるDiscoverリンクをクリックします(ナビゲーションメニュー項目を表示するには、左下の Expand アイコンをクリックする必要がある場合があります)。 Discover ページで、事前定義された filebeat- *インデックスパターンを選択して、Filebeatデータを表示します。 デフォルトでは、これにより過去15分間のすべてのログデータが表示されます。 以下に、ログイベントといくつかのログメッセージを含むヒストグラムが表示されます。

ここでは、ログを検索および参照したり、ダッシュボードをカスタマイズしたりできます。 ただし、現時点では、Elastic Stackサーバーからsyslogを収集しているだけなので、それほど多くはありません。
左側のパネルを使用してダッシュボードページに移動し、 FilebeatSystemダッシュボードを検索します。 そこで、Filebeatのsystemモジュールに付属するサンプルダッシュボードを選択できます。
たとえば、syslogメッセージに基づいて詳細な統計を表示できます。

sudoコマンドを使用したユーザーとその時期を表示することもできます。

Kibanaには、グラフ化やフィルタリングなど、他にも多くの機能がありますので、お気軽に探索してください。
結論
このチュートリアルでは、システムログを収集および分析するためにElasticStackをインストールおよび構成する方法を学習しました。 Beats を使用して、ほぼすべてのタイプのログまたはインデックス付きデータをLogstashに送信できますが、Logstashフィルターを使用して解析および構造化すると、データがさらに便利になります。 Elasticsearchで簡単に読み取れる一貫した形式。